如何使用find查找文件并删除WAVECAR
时间:2025-10-29 作者:Jiaqi Z.
分类:小教程-材料计算
在使用VASP计算过程中,如果你设置LWAVE=.TRUE.的话,在计算结果中会生成一个WAVECAR文件。一方面来说,生成WAVECAR可以生成一个初始波函数,方便后续计算收敛。但在大多数情况下,这一过程是没有必要的(可能在之前的VASP计算教程里明确提及这一点的地方,也仅仅是在计算HSE能带时用到了)。因此,很多时候我们都会默认设置INCAR里面的参数LWAVE=.FALSE.。
而事实上,总会有一些人(当然也包括我。。)在写输入文件时忘记这一点,而生成了非常非常大的WAVECAR文件,如果提前意识到,直接使用rm命令删掉当然可以。但如果忘记了呢?你会继续下去一直计算,而这时候大概率你也不会想起来要删除它。计算目录越来越多……计算文件越来越大……而这时候,当你下载目录到本地时……你会意识到WAVECAR(也可能会有CHGCAR)浪费了你大多数的时间
更严重的情况,如果你长时间不删除这些文件的话,服务器硬盘总是会满的……往小了说,对于超算来说存储空间也是花钱买来的;往大了说,如果是用自己课题组的服务器,硬盘满了,自己和别人都算不了了(无法写入文件)……
这时,你可能会想删除掉所有的WAVECAR。但是,一个一个删太慢,有没有一次性的方法删除?
什么是find命令?
在Linux当中,find命令可以用来在指定目录下查找文件和目录。一个基本的格式是find [路径] [条件] [动作]。
其中,路径表示你要查找的目录路径,例如,在当前目录下查找,可以使用find . [条件] [动作]表示(事实上,直接执行也表示当前目录)
条件可以用来指定要查找的文件,有好几种可以使用的选项,我们下面列举几个可能会用到的:
-name表示要查找的文件名,可以使用通配符,例如find . -name roselia表示在当前目录下寻找名字叫做roselia的文件。find . -name *.txt表示在当前目录下寻找后缀名为.txt的所有文件。如果希望查找多个文件,可以使用-o分隔(表示或),例如,find . -name yukina -o -name rinrin表示在当前目录下查找文件名为yukina或rinrin的文件(等价于查找两个文件)
(不要问我怎么查找同时满足名字为yukina和rinrin的文件…… 除非你的文件是类似薛定谔的猫那样的状态……)
type表示文件类型,包括f普通文件,d目录等
在目前的使用场景下,这些已经足够大多数情况了,如果还需要其他的参数(如-size, -user等),可以去网上查找相关资料。另外,上面两个参数可以混合使用,例如find ./roselia -name nonchan -type f表示在当前目录下的roselia子目录下查找名字叫nonchan的文件
一个现在你就可以用的场景——查找任务目录
如果你在计算时有记录的习惯,可能会记录任务的队列号(在提交任务时,通常队列系统会在当前目录下生成一个含有队列号的文件,表示队列系统的输出信息,以slurm系统为例,可能会生成slurm-[JOBID].out文件)借助这个文件,我们就可以通过队列号查找到计算的目录,从而方便我们快速进入到对应目录而不用一次次cd了。
方法很简单,使用find ~ -name slurm-[JOBID].out即可输出文件所在的目录。把[JOBID]替换为你的队列号。例如,队列号为1441,则将其替换为slurm-1441.out(或者你也可以简单使用*-1441.out,但前提是没有其他类似的文件)。上述命令表示在家目录下寻找任务号为[JOBID]的输出文件。关于为什么是在家目录下寻找——你不可能每次查找的文件都在当前目录向下可以找到。
关于find命令的动作参数
当执行动作时,通常前面需要有一个选项-exec表示执行命令,在选项后面为要执行的命令,你可以使用{ }表示查找到的文件(占位符),使用\;表示命令结束。
在这个基础上,我们就可以解决最开始的问题了:如何删除当前目录中所有的WAVECAR文件?
(如果你想直接知道最开始的结果,可以看这里了!!但我强烈建议看明白前面,不然你很可能一会儿就忘了)
执行下面的命令:find . -name WAVECAR -type f -exec rm {} \;,具体原理结合上面的说明,应该很容易理解。类似的,如果希望删除CHGCAR和CHG文件,则可以使用find . -name CHG* -type f -exec rm {} \;(使用了通配符*表示CHG和CHGCAR文件)
务必注意:\;前面要有空格!!
前方小高能!!下面的内容作为补充,有点难,可以尝试理解一下
那如何同时删除WAVECAR和CHGCAR呢?借助-o命令,使用下面的命令:
find . \( -name WAVECAR -o -name CHGCAR \) -type f -exec rm {} \;
这里面使用\( \)作为括号提高优先级,也就是\( A -o B \) C表示 (A或B)且C,按照布尔运算规则也就是A或C且B或C。但如果没有这个括号的话,就会识别为A或(B且C)。
祝Roselia主唱凑友希那生日快乐!!
时间:2025-10-26
分类:BanG Dream!
今天是10.26号,是roselia的主唱凑友希那的生日,转发这条消息到5个群聊,她会像小猫咪一样对你撒娇,我试过了,是假的,但是确实是凑友希那的生日,祝她生日快乐



图片来源(按照图片顺序):
- aiai的推特(X)
- 小红书 @Momo
- 小红书 @瞿淮
如何结合CP2K+Multiwfn做ELF拓扑分析
时间:2025-10-27 作者:Jiaqi Z.
分类:材料计算
本文以NO2为例,介绍一下如何借助CP2K计算软件与Multiwfn处理ELF拓扑分析(后面也会稍微介绍一下电荷密度拓扑分析)
注:具体关于Multiwfn的使用方法在sob老师的Multiwfn手册里有详细的说明(http://sobereva.com/multiwfn/),此外,用Multiwfn做拓扑分析在博文(http://sobereva.com/108)内也有说明。
使用Multiwfn构建CP2K的输入程序
首先,构建体系结构。在这里我们构建的是分子结构,分子结构的信息可以在网站cccbdb当中找到(网站链接:https://cccbdb.nist.gov/exp1x.asp,在教程网站的首页下滑就有)。假设现在构建得到的NO2结构POSCAR如下所示:
NO2
1.00000
20.0 0.0 0.0
0.0 20.0 0.0
0.0 0.0 20.0
N O
1 2
Cartesians
10.0000 10.0000 10.0000
10.0000 11.0989 10.4653
10.0000 8.9011 10.4653
将这个结构文件导出为cif格式,在本地运行Multiwfn,导入cif文件后按照下面的内容输入(括号里面是说明注释):
- cp2k (生成cp2k输入文件)
- NO2-relax.inp (生成输入文件名)
- -1(选择计算任务)
- 3(对原子进行结构优化)
- 2(选择基组)
- 10(使用全电子基组——6-31G*)
- 8(设置K点)
- 1,1,1 (使用Gamma点)
- -7(设置周期性)
- NONE(体系没有周期性)
- 0(生成输入文件)
生成的文件比较大,整个文件包括结构信息,基组信息和选择的计算参数。在前面的部分找到&CELL ,后面的三行表示晶格常数。可能会和最开始的POSCAR文件有区别,之所以如此,是因为在使用Multiwfn设置参数的时候,如果选择有方向不是周期性(在本例设置为三个),那Multiwfn会设置真空层大小。为了确保计算正确性(因为下面的原子坐标可能会超出晶格范围),我们可以修改晶格常数(改回原来的20)
提交计算任务
在提交计算任务之前,请首先确保服务器内安装有CP2K。如果没有,请联系服务器管理员安装(需要root权限)。
对于我所在的课题组服务器而言,最新确认的是201服务器已经安装CP2K,在提交任务时使用下面的脚本提交到计算队列(这是针对slurm队列系统的提交任务脚本,如果是使用其他的队列系统,参考着这个,结合你所使用的系统修改指令就行。)
不要在本地登录节点跑任务,这对于超算使用来说不是好习惯!尤其是使用外面的超算集群更是如此!通常登录节点的性能有限,全给你跑任务,别人根本没法用。哪怕是在localhost节点,在跑任务的同时后面有人提交任务的话,计算性能也不会得到充分发挥!!
#!/bin/bash
#SBATCH -N 1
#SBATCH -n 104
cd $SLURM_SUBMIT_DIR
module load CP2K
mpirun cp2k.psmp -i NO2-relax.inp >cp2k.out 2>cp2k.err
注意,这里面的NO2-relax.inp为当前计算的输入文件,你需要根据实际情况修改它。当然,如果你愿意的话,设置一个固定的输入文件名作为cp2k计算也行。例如,使用yukina.inp。另外,核数也必须根据实际情况修改,不然你在64核的机器上排104核的任务,肯定算不了。
将刚才的输入文件(NO2-relax.inp)和提交任务脚本放在同一个目录下,提交任务等待结果(按照上面脚本设置的,输出文件在cp2k.out里,当然你要更改也行,毕竟>表示重定向输出(见计算教程的Linux部分“高级Linux命令-管道与重定向”一节)。
优化完成查看输出文件cp2k.out(或者你设置的输出文件名),在最后找到收敛精度的表示如下,当四个全是YES时,表示结构优化达到收敛:
OPT| Maximum step size 0.0029693064
OPT| Convergence limit for maximum step size 0.0030000000
OPT| Maximum step size is converged YES
OPT|
OPT| RMS step size 0.0013574324
OPT| Convergence limit for RMS step size 0.0015000000
OPT| RMS step size is converged YES
OPT|
OPT| Maximum gradient 0.0001631261
OPT| Convergence limit for maximum gradient 0.0004500000
OPT| Maximum gradient is converged YES
OPT|
OPT| RMS gradient 0.0001049782
OPT| Convergence limit for RMS gradient 0.0003000000
OPT| RMS gradient is converged YES
计算自洽
将计算得到的NO2-relax-1.restart文件下载到本地,使用Multiwfn打开,按照下面的方式设置输入参数:
- cp2k(生成cp2k输入文件)
- NO2-scf.inp(输入文件名)
- -1 (选择计算任务)
- 1(计算能量)
- -7(设置周期性)
- NONE (不设置周期性结构)
- 2(设置基组)
- 10(选择6-31G*基组)
- 8 (设置K点)
- 1,1,1(Gamma点)
- -2(很重要!生成molden文件!)
- 0(生成输入文件)
进行ELF拓扑分析
完成后与结构优化类似将NO2-scf.inp文件作为输入文件上传至服务器,计算后得到后缀名为*.molden的文件,将其下载到本地后用Multiwfn打开,选择2进行拓扑分析,在-11里选择需要进行分析的内容(使用CP2K计算完成后可以直接处理ELF、波函数等数据)。我们是要进行ELF拓扑分析,于是选择9。
然后选择6寻找CP点。对于我们这种小分子体系,直接使用默认即可(1000个点),如果体系比较大,可以在11里设置每个球里寻找的点的个数。完成设置后使用-1可以以每个原子为中心寻找CP点;如果体系比较大,原子数比较多的话可以使用-2指定球心对应的原子。
按照sob老师的介绍,Multiwfn对拓扑计算的效率很高。在本例中,我们使用四核本地计算机处理,仅用了一两秒钟就结束了。完成后-9返回,并使用0查看拓扑点,如图所示。由于对ELF而言我们主要关注(3,-3)点,也就是ELF的极大值点,在旁边的复选框把其他点给去掉,可以发现,NO2除了在化学键上有类似于键的成键外,在原子外面也有孤对电子。在网站上(https://zh.webqc.org/lewis-structure-of-NO2.html)可以查到NO2的路易斯结构式,与计算结果一致。

进行电子密度拓扑分析
类似地,我们也可以对电子密度进行拓扑分析,首先关闭现有的窗口(按RETURN)返回命令行,在-11选择计算模式中选择1(电子密度),重复上面的步骤(找点、可视化)。与ELF相比,电子密度拓扑的速度更快(这是因为它的CP点更少),我们得到的所有CP点如图所示(为了可视化清楚,使用棍状模型,紫色点表示(3,-3)CP点,在电子密度中表示原子核;而橙色表示(3,-1),对应于键心。除此之外还有:
- (3,+1)表示环心
- (3,+3)表示笼心

注意:在寻找拓扑结构时,有一个Poincare-Hopf关系,即原子核-键心+环心-笼心=1,如果满足这个关系,则表明所有CP点已经找到。在生成图片后,Multiwfn会自动计算,并生成如下的内容:
The number of critical points of each type:
(3,-3): 3, (3,-1): 2, (3,+1): 0, (3,+3): 0
Poincare-Hopf verification: 3 - 2 + 0 - 0 = 1
Fine, Poincare-Hopf relationship is satisfied, all CPs may have been found
对于ELF拓扑分析而言,大概率不会找到全部的点,这并无所谓,只要对所研究的内容是没错的就行——主要关注(3,-3)点,而对于其他点通常不关心,也就没有必要关注是否满足上面的等式了。如果实在担心是否找全所有的点,可以切换球半径或点数,进一步查找。
除此之外,如果关心具体的CP点的信息(例如对应的电子密度多大),可以使用拓扑分析里的7功能,选择要研究的CP点查看。具体的在Multiwfn手册2.6、2.7小节。此外,借助8功能可以连接在(3,-3)和(3,-1)之间生成拓扑路径,通常表示化学键,具体的介绍可以查看网站(http://sobereva.com/108)
志崎桦音照片(2)
时间:2025-10-20
分类:BanG Dream!
好长时间没更新网站了,攒了好多“老婆”的照片,这次发一下。








服务器终端程序MobaXterm安装包
时间:2025-09-10
分类:材料计算
如题,这是MobaXterm的安装包,你可以直接点击这里下载。
下载完成后,如正常程序一样解压、安装,安装完成后进入程序,点击上方Session-SSH,输入服务器IP地址(在注册账号时会提供ip地址)
完成后双击左侧IP地址进入服务器,输入用户名和密码(注意:密码看不见,屏幕上不显示是正常的)即可。用户名和密码会在创建账户时提供。
non酱の照片1
时间:2025-07-26
分类:BanG Dream!
这是non酱在海宁活动时化妆的照片……好看……老婆……
你知道的,non酱一直是我的主人(bushi)







使用sed与正则表达式修改INCAR参数
时间:2025-07-02 作者:Jiaqi Z.
分类:材料计算
在材料计算的教程中,我们介绍了关于使用Linux的sed命令进行文本替换,其基本格式为sed -i "s/[原字符串]/[替换字符串]/g" [文件路径名]。利用这个方法,我们可以对INCAR文件中的参数进行替换。例如,我们希望将EDIFF从1E-5改成1E-6,可以使用命令sed -i "s/1E-5/1E-6/g" INCAR。
当然,这种方式有一个缺陷:如果INCAR的参数有多个相同的值,如何让命令只修改对应的参数?例如,我们希望修改自旋极化开关ISPIN让其从1变成2,但这个过程可能会使得其他参数(如ISTART)也会发生变化,这显然不是我们想要的结果。
也许……把关键字也加到命令里是可行的……
例如,我们尝试sed -i "s/ISPIN=1/ISPIN=2/g" INCAR,这种方法确实可以只修改ISPIN参数。但是,它忽略了等号两端的空格。对于一些工具(如vaspkit),在生成文件时会带有空格。那么,如果我们直接把空格加上呢?显然也是不行的,因为我们不知道有多少个空格。
注:在INCAR中查看有多少个空格,直接输入在命令中是一种“下策”,因为我们希望将这个功能“普适化”,以便在更多的场景下适用(无论有多少个空格)。甚至,以后可以将其用于for循环或者脚本中(我们后面会给一个脚本的使用例子)
答案是使用正则表达式。
关于正则表达式
在正则表达式中,使用\s符号表示所有空白符,使用\t表示制表符等。显然,空格应当是使用\s表示。但是,如何解决多个空格的问题呢?在正则表达式中,我们可以使用+表示前面的字符出现一次或多次,使用*表示前面的字符出现零次或多次
注意:这里的*不是“通配符”的那个符号。另外,这里的\实际上就是其他大多数程序语言中所表示的“转义字符”
因此,如果我们想要匹配类似于ISPIN = 1这样的字符串,可以用正则表达式写作ISPIN\s+=\s+1(可以自己尝试理解它)。在sed当中使用它,需要使用参数-E(因为像+这种符号属于扩展正则表达式)。综合一下,如果我们希望将ISPIN从1改成2,则可以写作sed -E -i "s/ISPIN\s+=\s+1/ISPIN = 2/g" INCAR
进一步,像上面这样仅使用正则表达式匹配空格算是“中策”,而“上策”则是使用不考虑初始数值,只使用关键字。例如,在设计脚本时,如果在用户使用时还需要提供原来的值,会稍显多余。简单的方法是无论后面的值是多少,直接改成我们想要的数值即可。在正则表达式中,使用\S表示非空白字符(还有\w,表示数字、字母和下划线,二者是不同的,前者范围更大)
如果考虑这种方法,可以将命令写成下面这样:sed -E -i "s/ENCUT\s+=\s+\S+/ENCUT = 600/g" INCAR。这种方式可以将ENCUT设置为600(无论原先的数值是400、520还是800还是其他数值)
一个扩展脚本
我们下面提供一个示例脚本,用户可以直接在当前目录下运行这个脚本,输入要修改的参数和想要的值,脚本会自动修改:
#!/bin/bash
# 修改INCAR参数
read -p "Parameter: " keyWord
read -p "Value: " value
sed -E -i "s/$keyWord\s+=\s+\S+/$keyWord = $value/g" INCAR
echo "Done!"
你可以将这个程序集成到更大的程序中(类似于vaspkit带有菜单功能引导)
Roselia Live 「Sei stark」返图
时间:2025-06-16
分类:BanG Dream!
老婆们……嘿嘿……













使用lobster进行COHP分析
时间:2025-04-09 作者:Jiaqi Z.
分类:材料计算
发布后第一次更新:2025-04-10
注:这部分后续可能会加入材料计算系列教程中
什么是COHP
晶体轨道哈密顿布居(Crystal Orbital Hamilton Population, COHP)是一种用于分析固体材料中原子间化学键性质的工具,由Dronskowski和Blochl在1993年提出[1]。其核心思想是通过计算哈密顿量矩阵元在原子轨道基底上的投影,定量评估相邻原子间轨道的成键(bonding)或反键(antibonding)相互作用。 COHP将能带结构能量分解为原子轨道对的相互作用能分布;从化学角度更直观地说,它是相邻原子对之间的"键权重"态密度。
与晶体轨道重叠布居(COOP)不同,COHP直接关联哈密顿量能量而非重叠积分,因此更适用于金属和半导体等强离域体系的键合分析。COHP的计算公式为:
其中,和为原子轨道系数,为哈密顿量矩阵元。负值COHP表示成键态(降低体系能量),正值则为反键态(升高体系能量)。
COHP图谱能明确展示成键(bonding)和反键(antibonding)对能带能量的贡献,通常与态密度(DOS)图并列呈现(DOS仅显示电子分布,而COHP揭示其键合特性)。正如对电子态密度(DOS)积分可得到体系总电子数,对COHP进行能量积分则可量化特定原子接触("化学键")对能带能量的贡献:换言之,积分COHP(ICOHP)的绝对值反映了键强。
如何使用COHP分析成键or反键
计算费米能级以下的COHP积分,如果积分小于0,则表示成键;如果大于0则表示反键。
使用VASP计算COHP的方法
1. 结构优化
如同正常的结构优化一样,在此不赘述。
2. 自洽计算
与一般的自洽类似,但需要注意以下几点:
ISYM需要设置为-1- 由于处理COHP需要读取WAVECAR文件,因此需要保留WAVECAR(
LWAVE=.TRUE.) - 需要设置一个较大的
NBANDS
其中在设置NBANDS时可以首先忽略掉这个参数,直接提交任务进行自洽计算,在开始时查看OUTCAR中NBANDS的数值(使用grep命令,具体方法请详见材料计算教程中的“Linux基础-高级Linux命令-grep匹配字符串”一节)。通常来说,默认数值偏小,一般设置为默认数值的1.5-2倍。
例如,在计算时默认NBANDS=300,则可以在INCAR中设置NBANDS=500左右。
3. 使用lobster处理COHP
在服务器上使用lobster计算投影以获取COHP,(如果你是我所在课题组的成员,课题组内106节点服务器已配置lobster,其他节点如224待测试,使用前需要module load lobster,建议直接使用后面的提交任务脚本在队列系统使用)对于其他课题组,建议寻求组内帮助,或联系超算管理员。
2025-4-10更新:课题组内服务器224和105已配置lobster,导入方法和106节点相同。
在使用lobster时需要准备一个输入文件lobsterin,一个常见的模板为:
# 设置起止能量(eV)
COHPstartEnergy -10
COHPendEnergy 5
usebasisset pbeVaspFit2015
# 设置轨道
basisfunctions C 2s 2p
# 考虑两个原子间的COHP
cohpbetween atom 1 atom 2 orbitalwise
gaussianSmearingWidth 0.05
# SkipDOS 跳过DOS计算
# 保存投影文件
saveProjectionToFile
# loadProjectionFromFile 读取投影文件
其中一些参数解释如下:
COHPstartEnergy和COHPendEnergy:在绘制COHP时考虑的能量范围,类似于计算态密度时设置的EMIN和EMAXusebasisset:对于VASP计算而言,使用pbeVaspFit2015总是没错的[2](除此之外还有Budge)basisfunctions:设置电子轨道,这一部分需要参考你所使用的赝势POTCAR文件。**注意:不同的赝势版本对应不同的轨道,例如,Ti_pv和Ti相比,前者多了3p轨道;Ti_sv又比Ti_pv多了3s轨道。你所使用的轨道需要根据POTCAR对应版本设置(使用grep TIT POTCAR查看每个元素对应版本),具体所考虑的轨道可以参考网站https://www.vasp.at/wiki/index.php/Choosing_pseudopotentials里的Recommended PAW potentialscohpbetweenatomatom orbitalwise:考虑第m个原子和第n个原子之间的cohp,其编号根据POSCAR文件排序(可以借助VESTA软件在可视化当中查看原子编号。双击原子在下方会有如“Atom: 1”的字样,表明这是第1个原子。orbitalwise表示计算投影cohp(类似于PDOS一样可以查看每个轨道的贡献)gaussianSmearingWidth:高斯展宽。如果VASP中设置ISMEAR=0,则需要在这里设置展宽(INCAR中的SIGMA);如果使用的是ISMEAR=-5(正四面体方法),则可以忽略这个参数SkipDOS:跳过DOS计算,lobster可以计算处理DOS,但相比其他脚本如Vaspkit,功能不是太好,因此一般可以选择忽略DOSsaveProjectionToFile:保存投影文件,cohp在计算投影时可能耗费的时间较多,因此将其保存下来可以方便之后使用loadProjectionFromFile读取而加快处理速度。
将文件设置完成后执行lobster即可得到处理后的文件。在输出结果中需要关注abs. charge spilling表示spilling误差,如果误差小于5%则表示计算正常(5%是官方给的数据,一般建议为2%)。
4. 绘图与后处理
在绘制cohp时需要使用wxDragon,可以在官网下载,也可以直接点击这里下载(注意:测试发现官网上的新版本在导出xy格式时有问题,需要“回调”至老版本。如果你没有安装,可以直接在这里下载可用于数据导出的老版本;如果你已经安装,无论是官网或者2025年4月10日之前在本篇文章对应链接下载的,需要删除原有安装包与解压文件,重新解压新文件)。下载完成后打开,将服务器上的COHPCAR.lobster下载到本地并导入软件中,选择合适的轨道进行可视化,完成后将数据导出为XY格式的文件并使用Origin进行绘图。(wxDragon的UI界面比较老)
注意:注意!注意!在开始时我们所说COHP在费米能级以下积分为负表示成键,积分为正表示反键。但在使用wxDragon绘制COHP时,为了和COOP相对应,在绘制COHP时通常设置为相反数(即-COHP),此时积分为正表示成键,积分为负表示反键!
提交任务脚本
下面是一个在slurm队列系统提交lobster任务的一个简单脚本(sub.lobster),对于我所在课题组内的成员而言可以直接使用(如提交vasp任务一样提交即可,使用sbatch sub.lobster),对于其他课题组而言,也可根据下面的格式进行修改以适配不同的队列系统(如pbs等),具体请咨询你的导师、你的课题组同学或者超算相关管理员。
你可以在这里直接下载脚本文件到本地,点击下载
#!/bin/bash
SBATCH -n 56
SBATCH -N 1
打印任务信息
cho "Starting job $SLURM_JOB_ID at " `date`
cho "SLURM_SUBMIT_DIR is $SLURM_SUBMIT_DIR"
cho "Running on nodes: $SLURM_NODELIST"
# 执行任务
## 载入lobster
module load lobster
##unlimited the stack size
#ulimit -s unlimited
lobster > lobster.out 2>lobster.err
# 任务结束
echo "Job $SLURM_JOB_ID done at " `date`
日麻系列教程1:日麻役种常见一览
时间:2025-03-12 作者:Jiaqi Z.
分类:桌游
这套教程是专门为同学学习日麻所写的,主要是为了帮助他们更容易记住这些役种。在开始学习役种之前,我们需要首先明确几个名词:
- 门清:没有吃牌、碰牌、明杠、加杠的行为(只有暗杠也算门清)
- 副露:有吃牌、碰牌、明杠、加杠
- 风牌:东、南、西、北
- 三元牌:中、发、白
- 字牌:风牌+三元牌
- 老头牌:数字1和数字9(1万、9万、1索、9索、1筒、9筒)
- 幺九牌:老头牌+字牌
我们首先会列出常见的役种列表,在后面会详细说明它们的含义
役种列表与记忆方法
- 一番役:【立直】、断幺九、【平和】、【一发】、【门前清自摸】、【一杯口】、役牌
记忆技巧:可以简记为“立断平一发自摸一杯口”,这是因为这些役种往往组合出现,后面还有一个“役牌”。
- 二番役:<三色同顺>、三色同刻、三杠子、三暗刻、小三元、<混全带幺九>、对对和、【七对子】、混老头、<一气通贯>
记忆技巧:几乎所有带“三”的役种都是二番役,还有和对子刻子有关的七对子,对对和。
-
三番役:<纯全带幺九>、<混一色>、【二杯口】
-
六番役:<清一色>
注:上述役种中带【】表示为门清役,即只有门清状态下才能成立;<>表示食下役,即副露下减一番。上述役种中带颜色的表示存在上位役满役种
记忆技巧:可以将“混一色”和“清一色”统称为染手,即可以记忆“食下役”为“三色、一气、全带、染手”,其中全带包括“混全带幺九(二番)”和“纯全带幺九(三番)”;染手包括“混一色(三番)”和“清一色(六番)”
-
常见的役满:四杠子、四暗刻、大三元、清老头、字一色、绿一色、小四喜、国士无双、九连宝灯
-
双倍役满(有些规则也记为役满):四暗刻单骑、大四喜、国士无双十三面、纯正九连宝灯
偶然役(不一定能做成的役,只有一番和役满)
- 一番:海底捞月(最后一张牌自摸)、河底摸鱼(最后一张牌荣和)、岭上开花(开杠后摸牌正好和牌)、抢杠(和别人加杠的牌,听国士无双时可以抢暗杠)
- 役满:天和(亲家配牌时直接和牌)、地和(子家在前面无吃、碰后第一张摸牌直接和牌)
役种详解
基本和牌型:m*AAA+n*BCD+EE(共14张)
术语:
- 刻子:AAA(三个完全相同的牌),通常包含碰牌所成的“明刻”以及手牌中的“暗刻”
- 顺子:BCD(三个花色相同、数字相连的数牌,例如234万、789索、123筒)
- 面子:刻子+顺子
- 对子:两个完全相同的牌
- 雀头:EE(对子)
- 两面:两个花色相同、数字相邻的数牌(不包括12、89),例如45万、34索、78筒
一番役
- 立直(门清役):门清听牌
- 断幺九:所有牌均不含幺九牌
- 役牌:包含有场风/自风/中/发/白刻子(/表示“或”)
- 平和(门清役):四组面子均为顺子+雀头不是役牌(场风、自风、三元)+听牌为两面顺子听牌
- 一杯口(门清役):两组完全一样的顺子(例如345万345万)
- 门前清自摸(门清役):在门清条件下自摸和牌
- 一发(门清役/立直限定):立直后在一巡内和牌(立直后一圈内和牌),且中间无吃牌、碰牌、杠牌
二番役
- 七对子(非基本型,门清役):7组不相同的对子
- 三色同顺:三组花色不同、数字相同的顺子(例如345万345筒345索)
- 三色同刻:三组花色不同、数字相同的刻子(例如333万333筒333索)
- 混全带幺九(食下役):五组面子和雀头均“带有”幺九牌(1、9和字牌)
- 一气通贯(食下役):相同花色的123,456,789三组顺子
- 对对和:所有面子都是刻子
- 三暗刻:三组暗刻
- 三杠子:三组杠子(明杠、暗杠、加杠均可)
- 混老头:五组面子和雀头均为幺九牌(1、9和字牌)
- 小三元:中、发、白任意两个刻子加另一个对子
三番役
- 纯全带幺九(食下役):五组面子和雀头均“带有”老头牌(1、9)(即“混全带幺九”无字牌)
- 混一色(食下役):五组面子和雀头均为同一种花色的数牌和字牌
- 二杯口(门清役):两组“一杯口”(例如345万345万789索789索)
六番役
- 清一色(食下役):五组面子和雀头均为同一种花色的数牌(“混一色”无字牌)
役满
- 四暗刻(门清役):四组暗刻
- 四杠子:四组杠子(明杠、暗杠、加杠均可)
- 清老头:五组面子和雀头均为老头牌(1、9)
- 大三元:三组中、发、白的刻子
- 小四喜:风牌(东、南、西、北)任意三组刻子加另一个对子
- 国士无双(非基本型,门清役):19万19索19筒+东南西北中发白,加其中任意一种的对子
- 字一色:所有牌都是字牌(风牌或三元牌)
- 绿一色:所有牌都是2、3、4、6、8索或发组成的
- 九连宝灯(门清役):同种花色的1112345678999+同花色另外一张
双倍役满
- 四暗刻单骑(门清役):四组暗刻+最后剩余单张听牌
- 大四喜:风牌(东、南、西、北)的四组刻子
- 国士无双十三面(非基本型,门清役):手牌为19万19索19筒+东南西北中发白,听其中的任意一张
- 纯正九连宝灯(门清役):手牌为同种花色的1112345678999,听同花色另外一张
(下篇预告:介绍如何“简单”地计算点数)
Roselia Live 「Stille Nacht, Rosen Nacht」上海官方返图(补充)
时间:2025-02-20
分类:BanG Dream!










Roselia Live 「Stille Nacht, Rosen Nacht」上海官方返图
时间:2025-02-16
分类:BanG Dream!
这是“老婆们”的照片返图……嘿嘿……












【快报】从刘谦魔术看排列组合与冒泡算法
时间:2025-01-31 作者:小七Seven@科普小白说
分类:科普
注:继去年讲解刘谦魔术之后,这又是一篇“快报”,用最短的方法给大家解释第一个魔术种关于排序问题所使用的——冒泡算法
回顾魔术效果
让我们从头回顾一下第一个“举杯”的魔术过程:
- 把杯子、筷子和勺子随意按照顺序摆放
- 将筷子和左边互换
- 将杯子和右边互换
- 将勺子和左边互换
- 左手举起最左边的东西,右手举起最右边的东西,放下左手的东西,右手一定是杯子
关于“冒泡排序”
在表演完这个魔术之后,网上有一些评论提到了“冒泡排序”。在某种程度上,它和这个算法是类似的,因此我们先用一些篇幅说明这个算法,在最后我们来解释一下——为什么这个魔术实际上不是冒泡排序。
冒泡排序(Bubble Sort)是最简单和最通用的排序方法,其基本思想是:在待排序的一组数中,将相邻的两个数进行比较,若前面的数比后面的数大就交换两数,否则不交换;如此下去,直至最终完成排序。由此可得,在排序过程中,大的数据往下沉,小的数据往上浮,就像气泡一样,于是将这种排序算法形象地称为冒泡排序。 ——以上内容转自“百度百科”
正如上面所解释的那样,冒泡排序实际上是计算机领域一个排序问题算法。
也许你会想问:为什么计算机需要排序算法?类比查字典这个过程,以《新华字典》为例,是按照拼音字母顺序排序的,也正因如此,对于知道读音的情况,熟悉字典的人可以不用查询前面的目录就可以定位到后面对应拼音的位置。对于英语词典更是如此。从计算机的角度看,有序数据更有利于后续的查找。
排列与组合
对于熟悉高中数学的人来说,这一部分可以跳过去
正如前面所引用的内容,冒泡排序需要对所有数字两两比较大小。于是涉及到一个问题——最多需要比较多少次?之所以选择“最多”的次数,是为了得到评估算法效率的时间复杂度。
让我们进一步抽象这个问题,就可以化简为:给定个数,需要需要选出2个数,最多有几种选法?或者再进一步推广一下,假设有个数,需要选出个数,最多有几种选法?
排列——考虑顺序的组合
以这个魔术为例,有3个物体,首先考虑一个问题,有多少种排列方法?让我们把三个物体暂时抽象成123三个数字,在选择第一个物体时,可以有3种选法;对第二个物体,由于第一个物体已经选定,所以只有2种选法了;对于第三个物体,则只剩下1个物体。于是最终的排列方法就是
进一步,假设我们有个物体,则第一个选择有种选法;第二个物体有种选法;以此类推,最后一个只有1种选法,所以最终的排列方法就是
上述运算我们也可以表示为“阶乘”,即
再考虑一下,如果在个物体当中选个物体进行排列,将排列的个数记为或者,参考上面的方法,可以得到结果为
组合——再把同一组删掉
正如标题所说的那样,所谓组合,就是在排列的基础上不考虑顺序,例如,对于排列而言,AB和BA是不同的,但组合中二者是相同的。因此,在计算组合时,我们只需要将之前排列的结果,除以每个组合中全排列的个数即可。
全排列:指的是将个物体中选出个进行排列,即开始时所考虑的
根据上面的解释,将个物体选个进行组合,其结果记为,表达式为
例如,将3个物体选2个,带入表达式可以计算出,即共有3种选法。
冒泡算法——一种“低效”的排序算法
在前面,我们提到:冒泡排序需要对所有数字两两比较,对于比较结果较大的数字,向后排(假设按照升序,当然也可以定为“降序”,这不是算法关键)。让我们假定一个例子,假设有这个一组数字:5,2,3,1,6;按照冒泡排序算法,首先比较5和2,发现5较大,则往后排,变为2,5,3,1,6,进一步比较5和3,发现5较大,则将5继续向后排,变为2,3,5,1,6,以此类推,当排序变为2,3,1,5,6时,将5和6比较,发现6更大,则将6放在后面,结束排序。
进一步对2进行移动,依次为
- 2,3,1,5,6(2和3比较后)
- 2,1,3,5,6(3和1比较后)
- 2,1,3,5,6(3和5比较后)
再对2进行移动(始终移动最前面的数字),依次为
- 1,2,3,5,6(2和1比较后)
- 1,2,3,5,6(2和3比较后)
最后,对1进行移动,和2比较后发现2比1大,结果最终排序为“1,2,3,5,6”
让我们看看上面总共进行了多少次比较:10次!这看似是一个小数目,但这仅仅是5个数据的比较,如果是10个呢?20个呢?甚至100个1000个呢?利用前面的排列组合知识可以计算得到,假设有个数据,选择2个进行比较,一共有
可以发现,比较次数是与数据量成平方关系上升,这在数据结构中记为时间复杂度为
这种平方数量级的时间复杂度实际上效率是很低的,尤其是随着数据量的提高。因此,在算法设计上,人们提出了更多高效率的算法例如归并排序算法(采用分治法),此时时间复杂度可以达到。下面的图片展示了对于数据个数从1-10情况下两种时间复杂度的比较。可以看到,相比于,的增长速率更低
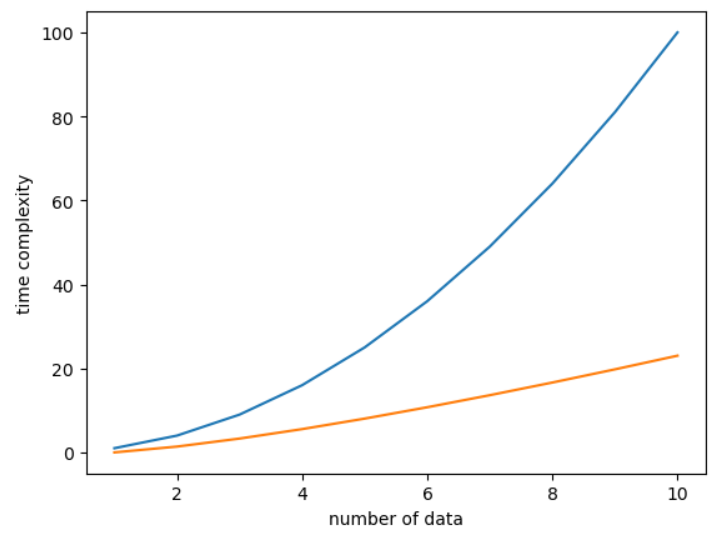
上图为时间复杂度比较,其中蓝线表示,橙线表示
最后的解释
首先让我们定性说明一下——为什么这个魔术的原理不是冒泡算法。原因很简单,冒泡算法是需要比较的,同时我们可以很容易证明,对于3个物体,实际上比较3次应该是有固定顺序的。但显然事实不是如此。这是因为我们在交换时实际上没有进行比较。
那这个魔术是怎么变的呢?让我们再来看一下魔术步骤(我们省略掉开头的调整顺序和最后的“举杯”):
- 将筷子和左边互换
- 将杯子和右边互换
- 将勺子和左边互换
我们假设将筷子记为A、杯子记为B、勺子记为C,在一开始会有6种情况(全排列),经过第一步移动,只会出现4种情况:ACB、ABC、BAC和CAB,经过第二次移动,这四种情况会变为:ACB(前两种一样)、ABC和CAB;对于B在最后的情况,第三步移动是多余的(因为不会影响B的位置),而对于ABC,第三步会变为“ACB”。
简单来说,最后的顺序只有两种可能——筷子、勺子、杯子和勺子、筷子、杯子。无论哪种情况,最右边一定是杯子。
一点题外话
与去年相比,很多人认为魔术原理更简单了。正如去年所说的那样,魔术的精髓并不是这个原理,而是表演的过程。事实上,从这个原理出发,可以设计出来这个魔术,难道不是更厉害吗?
如何从零开始进行程序设计
时间:2025-01-13 作者:Jiaqi Z.
分类:小教程-机器学习与人工智能
这一篇虽说是放在机器学习分类下,主要是为课题组内的同学所准备的,但这篇文章所说的一些想法,可能也适用于大多数程序设计的过程(无论是在科研过程中需要写程序、或者是做程序设计课程的课程设计等)。
本篇不会讲解具体的程序设计语言,例如Python、C语言等,而是一种通用的思考方法,可以帮助你更快上手进行一个较大的程序设计。
第一步:明确问题与需求
永远不要一开始就敲代码,仔细思考一下:要解决什么问题。大多数编程活动都是任务驱动或者问题驱动。例如,对于在校大学生而言,写程序可能是为了解决课本上的一个问题,或者老师的一个任务需求,又或者是论文上需要的一部分;对于软件工程师而言,写程序可能是为了实现产品经理的一个特定的需求,或者修复用户提出的一个bug等。盲目开始写程序,总是不可取的。
同时,在明确问题与需求之后,需要考虑的是:这段代码应该使用什么程序语言设计?例如,如果你是希望做机器学习与神经网络相关的,显然Python是更适合的;而像物理专业的一些理论计算,比如解方程等任务,可能使用MATLAB或者Wolfram Mathematica更方便;如果你是做嵌入式单片机的,那几乎就是C语言设计的……总而言之,选择一个合适的程序语言可能会让你的程序设计过程事半功倍。
如果你确实不知道该用什么编程语言的话,试试Python吧
第二步:拆分任务
程序设计的思维一定是模块化的思维,如果一个程序很小,例如判断一个数字是不是质数、或者使用欧几里得算法判断两个数字的最大公因数 等,只需要完成这一个任务就足够了。但通常情况下,使用程序解决的问题往往会很复杂,可能需要多个模块相互配合。这就如同一个公司要进行经营,需要各个部门的配合,其中每个部门都负责自己的内容,最后将其整合起来成为一个完整的公司架构一样。写程序的时候,也应当将任务进行拆分,拆分成一系列的“小任务”(也可以看作模块)。这个模块的大小可以因人而异(或者在具体的软件开发中,可能开发组内又有另外的分工),对于初学者而言,可能程序算法不是太熟练,此时可以将模块尽可能的小。例如,现在希望制作一个值日表安排程序,将一个时间段按照日期,每隔一定天数安排一个人,一共有6个人,按照顺序依次分配。此时我们的程序可能会拆分成这样几个任务:
生成日期-按照一定间隔取出日期-按照顺序安排6个人
注意:这些任务的划分是取决于程序设计者本人的(或者取决于项目开发组的)。
第三步:对每个任务进行拆分,设计步骤
有了具体的任务之后,我们就可以“逐一攻破”了。在程序设计的过程中,我们需要对每个任务进行进一步划分,将其划分为有限次数的步骤(这就是算法),这些步骤应当是确定的。例如,在上面的例子中,我们可能需要做这样几个算法(这些算法的每一步并不一定是一行代码,可能是多行代码,甚至有些步骤本身可能足够复杂到成为一个“任务”了)
- 读取起始日期和结束日期(yyyy1-mm1-dd1和yyyy2-mm2-dd2)
- 定义一个空的列表
dates(这个列表是广义上的列表,它可能是C语言中的数组,也可能是MATLAB等程序中的向量,也可能是Python中的列表) - 定义
i←0 dates[i]←yyyy1-mm1-dd1(这里面的←是一个比较常见的算法符号,表示将右面的值赋值给左边的变量)i←i+1- 查看
yyyy1-mm1-dd1+1(表示“下一天”)是否“小于等于”yyyy2-mm2-dd2,如果是,则进行第7步,否则进行第9步 yyyy1-mm1-dd1←yyyy1-mm1-dd1+1- 返回第4步
- 输出
dates列表
可以注意到,以Python为例,像第2步,第3步这些都是可以用一行表达式如dates=[]和i=0进行表示;但类似于第6步,查看某一天的下一天并不是一件“易事”(因为它涉及到一个月的最后一天的判断,甚至可能包括平年闰年的判断等),同时判断一天是否“小于”另一天也不是单纯的比较大小(可能需要三个数的比较),因此,我们可能会把第6步作为一个函数处理(完全可以把“函数”也看作是一种“任务”,但为了与前面的任务区分,我们这里使用“函数”,从程序设计的角度看,函数里面调用函数本身就是合理的)
第四步:从底层开始编写代码
这一步难度应该是“最低”的,因为它实际上就是用计算机语言把你前面所想的步骤表示出来。但是,在写代码的时候,有一些小技巧可以注意:
- 善用测试:任何人都不敢说可以一次写出正确的程序,大多数时间应当是调试、修改代码。因此,发现程序报错并不可怕,重要的是如何找到错误的地方。如果是一次性写完再测试,那工作量太大,且错误的可能性太大,因此,我们可以每写完一个任务或者一个函数,就测试一下函数的准确性。在测试的时候,可以在程序中以变量赋值的方式给定一些测试数据,或者使用像Python的
input()函数,以及C语言的scanf()等方式进行终端的输入(通常直接变量赋值是最方便的)。在输出时可以简单的终端输出,或者根据需要选择像文件输出等方式来判断输出格式的正确性。通常,在涉及底层算法时,其测试可以简单的终端输入输出;而涉及到交互时,可能会需要一些其他的方式(有时这可能需要前后端的配合,但从程序设计“哲学”的角度来看,前后端分离是必需的。)
还是以上面的例子为例,假设我们现在完成了函数addDate(date)函数,给定date函数返回它的下一天。在测试时,我们可以仅仅调用这个函数,给定几个特殊的date(例如,2024年2月28日、2025年2月28日、2023年5月30日、2025年1月8日、2024年12月31日等,可以看到,这里面包含了一个月最后一天,一年最后一天,平年闰年2月的判断,以及常规的日期),通过这几个测试例,可以很容易判断这个函数是否实现的预期的功能。如果测试通过了,可以想见,它在后面的程序中大概率也是正确的,如果测试不通过,一个函数的代码量也是比较小的,容易发现其中的错误。
以我个人的习惯为例,在完成一个函数时,我喜欢对其进行一个小的测试,判断它的功能是否正确;在完成一个大的任务时,我喜欢对其进行一个测试,判断它是否可以正确完成这个任务;在整个程序完成后,再对其进行测试,通常这时候就是判断各个任务之间的“衔接”是否合理。一个需要记住的是:越在早期排查出错误,越能避免后期造成更大更隐蔽的错误
-
善用AI:现在的程序设计,几乎AI是不可避免的。我也不反对程序设计中使用AI来生成一些代码。但是,需要特别注意的是:最多使用AI生成一个函数,千万不要使用AI生成一个“任务”,甚至整个程序,AI还没有那么强大,大概率会失控。此时出现的错误,非常难以排查。使用AI生成一个函数,甚至10行左右的语句实现一个功能,如果出现错误,人为排查是很方便的(详见第1条的善用测试)
-
平地起高楼,地基要打好:还是要本着底层设计的思路,千万不要想着“一口吃成个胖子”,再天才的程序员也做不到一次性写出上千行代码。慢慢来,一步一步来,从简单的开始像“搭积木”一样,最终实现复杂的功能不是难事。而且,不要羡慕别人能写几千、几万行代码,再复杂的代码也是由若干个功能实现的,可能每一个功能也就几十行代码。利用上面的方法,你也可以写出上千上万行代码。
-
一定要写注释!:把每一个函数做了什么,每一部分干了什么记录下来,在后期进行整合时会很容易(要不然你一定会“眼花缭乱”的)
双曲型、抛物型和椭圆型偏微分方程的区别
时间:2025-01-08 作者:Jiaqi Z.
分类:小教程
在数学物理方程(偏微分方程)中,我们了解了波动方程、热传导方程和泊松方程(或者拉普拉斯方程),并且也说,它们三个方程分别属于双曲型、抛物型和椭圆型。并且在“标准型”的讨论中,也了解了这些类型与存在直接相关的关系。
当听到“双曲”、“抛物”和“椭圆”时,免不了会联想到圆锥曲线,可以证明(或者其他教材中所说的那样),任何一个圆锥曲线,都可以写作下面的方程所表示的曲线
假设我们现在令和分别表示和,且等式两边同时作用于函数,则可以将上面的“圆锥曲线”写作下面的偏微分方程:
从而将这两个方程画上了“等号”。既然如此,我们就可以利用圆锥曲线的“形状”来定义微分方程的“类型”:
我们这里姑且不考虑参数,即只考虑最简单的这一“二次方程”。
-
假设这是一个椭圆方程,则利用已知的椭圆方程定义 不难得到,且,因此定义一个,可以得到对椭圆而言,
-
对于抛物线而言,假设一个最简单的方程 可以很容易得到且(若抛物线方程为,则),类似带入上面的定义,可以得到对抛物线而言,
-
对双曲线而言,其定义为 可以得到,从而对双曲线而言,。
代回微分方程
类似的讨论方法,让我们依次对三种“基本方程”进行讨论(假设我们只考虑齐次方程,因为非齐次项不影响方程类型)。
-
波动方程,其基本形式为 很显然,,利用圆锥曲线的讨论,这一判定式说明它是双曲型。
-
热传导方程,其形式为 其中,,从而,是抛物型
-
Laplace方程,其形式为 从而,判断,是椭圆型
关于杂谈的内容
时间:2024-12-23 作者:Jiaqi Z.
分类:杂谈
对于这个个人网页来说,目前已经成一定样式了,但总感觉还差点东西。差一点我自己的东西(当然,这网页里面每一个都是我自己写的)想了想,感觉还是做一个这种类似于博客性质的网页。正因如此,这个网页诞生了。
关于作者
与我的个人网页类似,这里面的作者大多数都是我,包括但不限于
- Jiaqi Z.
- “7小七Seven”以及其他类似如“小七Seven”、“小七”等名字
- Nana_Chan
- “Nana_L”或“Nana_R”
- “なな”或者带有叠字符号的“なゝ”(目前还没有使用片假名“ナナ”作为笔名)
- ……
但是,这里的作者也可能包括其他从别的网站转载的内容,或者课题组内其他人所写的内容,都会按部就班设置作者。
关于文章类型
目前共设置以下几种文章类型:
- 小教程:指的是一些单独的、或者目前还没有汇总在一起的教程,可能是课程的学习资料分享,也可能是一些小软件、小工具的使用方法等(注意:关于材料计算和机器学习两个分类,请在点开后打开对应内容查看);
- 科普:指的是一些给非相关专业的人看的文章,有些也可能是计划发在“科普小白说”公众号的草稿(相比于公众号里面的内容,这里的可能更加简单,随性)
- BanG Dream!:指的是一些关于BanG Dream!游戏的内容,一些玩游戏过程中的想法,一些音乐、图片分享,甚至可能包括游戏晒卡等都会在这里(当然也不排除有一些发电内容)
- 桌游:关于一些桌游相关的文章,有些可能是桌游规则整理、或者是一些桌游的感悟等。当然,关于桌游评测与桌游照片等,请去相关网页查看
- 音乐:一些关于音乐的相关内容,可能是分享一些歌曲,或者可能自己写了(或改了)一首歌也会发在上面,也有可能是关于音乐理论的文章
- 游戏:一些关于游戏的内容(这里面的游戏主要指除BanG Dream!和桌游以外的那些游戏,主要是电子游戏)
- 杂谈:一些目前还不知道该放在哪个分类下,或者确实不知道应该放在哪里的文章。
你也可以在左侧通过“全部内容”查看所有文章。其中有些文章可能属于多个分类,例如,关于BanG Dream!的音乐改编,有可能同时放在BanG Dream!和音乐两个分类下;关于音乐乐理的介绍,有可能放在“科普”或者“小教程”和“音乐”分类下。
更新频率
这个……就不好催更了吧……(没必要要求我每天都写杂谈吧)
联系方式
- QQ:3585318203
- 邮箱:zhangjq_sd@163.com
- Bilibili:UID 123645189
- Github:github.com/JackyZhang00
- 其他相关联系方式请通过主页对应分类查看
Roselia Live 「Stille Nacht, Rosen Nacht」官方返图
时间:2024-12-23
分类:BanG Dream!

















Linux当中for与VASPKIT“联动”
时间:2024-12-25 作者:Jiaqi Z.
分类:小教程-材料计算
在对VASP计算结果进行批处理时,有时需要借助于VASPKIT生成的文件,或者使用VASPKIT对数据进行分析。此时需要使用for循环,或者在脚本语言中实现对VASPKIT菜单的调用。
简单来说,我们希望找到一种命令的调用方法,模拟用户输入选项。而这种方法就是借助于echo命令和管道运算符。
注意:建议提前阅读教程内关于“高级Linux命令”一章的内容。
方法1
使用echo -e选项输出带有转义字符的文本,并借助于管道运算符|将输出的内容传递到vaspkit当中。例如,如果希望一次性生成静态计算的INCAR文件,可以直接写作:
[7Seven@localhost ~]$ echo -e "1\n101\nST" | vaspkit
运行后就可以看到vaspkit如同正常操作一般按照顺序执行对应的内容。其中,\n转义字符表示回车,即模拟用户进行回车操作(确认输入内容)
方法2
使用分号(;)依次表示所有的命令,并使用echo组合传递给vaspkit。例如,上述例子还可以写作:
[7Seven@localhost ~]$ (echo 1; echo 10; echo ST) | vaspkit
其中使用括号表示将括号内所有内容传递给vaspkit。在这一基础上,可以进一步做更复杂的操作。
在上述方法的基础上,可以使用for循环组合进行批量处理,并进行更复杂操作。例如,将所有当前目录下所有子目录内生成带有D3校正的静态计算INCAR文件,可以写作:
[7Seven@localhost ~]$ for i in *; do cd $i; echo -e "1\n101\nSTD3" | vaspkit; cd $OLDPWD; done
注意事项
vaspkit的调用方法取决于不同服务器,以所在服务器为准;- 在使用时,建议首先进行测试,确认vaspkit的选项顺序,在确保正确后再进行批量处理;
- VASPKIT参考文献:V. Wang, N. Xu, J.C. Liu, G. Tang, W.T. Geng, VASPKIT: A User-Friendly Interface Facilitating High-Throughput Computing and Analysis Using VASP Code, Computer Physics Communications 267, 108033 (2021). https://doi.org/10.1016/j.cpc.2021.108033