1.1 认识Linux目录
作者:Jiaqi Z.
知识点
- Linux命令格式
- 如何在Linux当中表示目录
- 绝对路径和相对路径
- 如何快速表示当前目录和上一级目录
命令格式
与Windows使用可视化界面不同,Linux大多时候使用命令行(shell)进行操作。因此,在Linux的学习过程中,一个最重要的任务,就是掌握一些常见的Linux命令。对于大多数科研课题组而言,Linux系统都是在远程云端服务器上,因此在本地往往只需要一个终端程序即可连接到服务器。一些常见的终端软件包括Xshell、MobaXterm、甚至VS Code1等。
如果你熟悉其他操作系统,可能听闻过类似于Windows Server,或者Linux的Ubuntu这样的操作系统。明明也可以使用可视化界面,为什么在科研过程中从来不会用到它们呢?(更严谨地说,在远程服务器上)。实际上,当使用可视化界面进行远程连接时,所产生的网络资源消耗是巨大的,通常需要更大的带宽,而使用命令行就可以提高数据传输效率。此外,更重要的一点是,使用命令行可以很容易实现批量处理,这在后续的章节会介绍到。
在Linux当中,输入命令通常采用的格式是命令 [-选项] [参数],其中中括号表示这个部分是可选的,即可以没有的。例如,当我们希望列出当前目录下所有文件时,可以使用ls直接输出,也可以使用ls -l以列表格式输出。
在后面可能会看到选项有多个的情况,此时为了简化,可以将选项合并在一起。例如,ls -l -a可以简化为ls -la。
命令与选项、参数之间是以空格进行分割,且这个空格不能省略。
目录表示方法
在Linux当中,所有目录都是以根目录/为起点,任何目录都是根目录的子目录。根目录下存在一些固定的目录(这些目录通常有特定的含义),例如,在根目录下有一个叫做bin的目录(通常写作/bin),它存放的都是二进制文件,也就是系统可以执行的程序文件。
在Linux当中,任何命令实际上都是可执行程序。你可以在/bin目录下看到后面所学的所有Linux终端命令。
另一个比较重要的位置是家目录/home,它存放的是用户个人文件。在这一目录下,你可以看到系统所注册的所有用户名。但是,这些文件夹大多数是无法查看的2。对于用户自己的家目录,通常也可以表示为~。通常来说,当你使用终端等连接登录时,默认的所在目录就是家目录~
绝对路径和相对路径
任何目录在操作时都具有两种表示方式,绝对路径和相对路径。正如目录表示方法所介绍的那样,任何目录都是从根目录开始的。因此在描述一个目录时,可以从根目录(即/)开始。例如,若你在你的家目录下有一个叫做vasp的目录,那么它的绝对路径就是/home/<你的用户名>/vasp。
在这种情况下,你可以将目录vasp理解为<当前所在目录>/vasp,即等价于/home/<你的用户名>/vasp。
千万不要写成/vasp,它表示根目录下的vasp目录。如果你希望特别强调当前目录,可以使用符号.(一个点)表示“当前目录”,即可以写成./vasp
然而,在这种情况下,回到当前目录的上一级目录是麻烦的,即在目前所学范围内,只能使用绝对路径。好在Linux提供了一个命令:..(两个点)表示上一级目录。因此,如果你当前处在目录/home/<你的用户名>/vasp当中,则..表示/home/<你的用户名>
在终端当中,..(两个点)表示父目录(即上一级目录),而一个点.表示当前目录。
这些符号(指令)在后续关于目录操作中都是可以使用的。
看到这里,可以思考下面的问题:如果在你的家目录下有两个目录python和vasp,此时你在/home/<你的用户名>/vasp目录下,如何可以快速表示python目录呢(不能使用绝对路径)?
答案:../python即可表示/home/<你的用户名>/python目录
1.2 目录操作
作者:Jiaqi Z.
知识点
- 如何显示当前目录下所有文件
- 如何创建目录
- 如何切换至其他目录
显示目录文件 ls
在这一节以及下一节,我们将讨论如何对目录和文件做基本的操作。无论是哪一种,一个最基本的前提是知道当前目录有哪些文件和目录,从而才能进行后续操作(例如编辑、删除、移动、进入目录等)。
在Linux当中,列出一个目录下所有文件使用的是ls命令。在没有任何参数与选项的前提下,它输出的结果就是当前所在目录下的所有文件和目录。以绝对路径和相对路径一节最后的例子为例,家目录下有vasp和python两个目录,当在家目录下执行ls命令时,结果如下:
$ ls
vasp python
同时,ls支持在后面添加一个参数表示要输出的目录。例如,在这一例子下,若在家目录当中执行命令ls vasp,将会输出vasp目录下的所有文件和目录。利用..表示上一级目录的用法,若当前处在~/vasp目录下,使用ls ..便可得到上一级目录(即家目录)下的所有文件和目录。
ls -l
下面介绍两个常见的ls选项,首先是-l选项,它表示以列表形式输出结果。例如,还是上面的例子,使用这一命令的结果为:
$ ls -l
total 0
drwxrwxr-x 2 zjq zjq 6 Aug 12 16:35 python
drwxrwxr-x 2 zjq zjq 6 Aug 12 16:35 vasp
每一个文件的输出结果可以分为9个部分,分别是:权限、文件硬链接数或目录子目录数、拥有者用户名、拥有者所在组、文件大小、文件修改月份、日期、时间、文件名。
关于权限,可以将其分成四部分:第一部分(一个字符)表示文件类型(这里的d表示目录),第二部分(三个字符)表示拥有者权限(rwx表示可读可写可执行),第三部分(三个字符)表示组用户权限,第四部分(三个字符)表示其他用户权限(r-x)表示可读,可执行但不可编辑。
对于文件硬链接数和目标子目录数,对于初始创建的文件而言,通常为1,而对于目录而言,默认为2(因为有两个子目录.和..)
有时,也可以使用ll代替指令ls -l,其二者是完全等价的。
ls -a
-a选项表示列出所有文件,包括隐藏文件。例如,在~/vasp目录下,使用ls -a命令,结果为:
$ ls -a
. ..
正如前面所介绍的那样,任何一个空目录都会默认有两个隐藏目录--自身和它的上一级目录。而这也解释了绝对路径和相对路径一节所介绍的.和..的本质,它们实际上就是任何当前目录下的两个子目录。
前面所介绍的-l选项和-a选项是可以合并使用的,此时可以将两个选项之间以空格分割,如ls -l -a,或者将两个选项写在一起ls -la。
当选项写在一起时,选项的排列顺序不重要。
与最开始介绍ls后面加参数表示目录一样,带有选项的ls同样可以在后面添加参数,例如,ls -a vasp表示列出当前目录下的vasp子目录下的所有文件和目录(包括隐藏文件)。
关于隐藏文件
隐藏文件是指在文件名前面加上.的,例如.bashrc。
隐藏文件在Linux当中的常见用途有:
- 配置文件
- 临时文件
- 缓存文件
- 等
总而言之,隐藏文件是为了防止误操作而存在的。(这可能与一些人认为的“隐藏文件是避免别人看到”不同)事实上,哪怕在Windows操作系统中,隐藏文件也是存在且方便查看的。
创建目录 mkdir
如果所有操作都在家目录下进行,那文件管理就太复杂了。试想一下,在科研里面算了好几年的结果,全部“一股脑”堆在一起,既难找,也容易忘记当时是做了什么。因此,一个好的目录管理至关重要。而前提,就是知道如何创建目录。
在Linux当中,创建目录的方法是使用mkdir命令。与前面介绍的ls,以及后面要介绍的cd不同的是,mkdir必须带有一个参数,表示创建的目录路径。对于刚开始接触的初学者,一个最简单的命令格式是:mkdir <目录名>,其中表示在当前目录下创建一个名为<目录名>的目录。例如,希望在当前目录下创建一个名为ML的目录,则可以使用命令mkdir ML。
你所写的路径名,应当是你所要创建的目录。这句话似乎有点绕,举个例子,如果你希望在/home/zjq/vasp下创建一个名为lattice的目录,则你需要运行的命令是mkdir /home/zjq/vasp/lattice。注意到,后面的路径实际上就是你要创建的目录。
切换目录 cd
在Linux当中,切换目录使用的命令是cd,通常来说,后面需要配合一个参数,表示要切换到哪里。例如,使用命令cd /home则是将当前目录切换到/home目录下。配合以..,可以使用cd ..切换到上一级目录。
思考:如果使用cd .,会得到什么结果?
答案:这个命令的含义是切换到当前目录,最终效果就是什么也不发生。
特殊的,对于家目录而言,除了可以使用cd ~外,Linux也支持直接使用cd,不添加任何参数实现这一功能,即二者是等价的。
错误处理
-bash: cd: <目录名>: Not a directory
cd后面的参数必须是目录,不能是文件。如果参数是文件,则会报该错误。
如果不知道哪个是目录,哪个是文件,可以使用ls -l查看第一个字符(文件类型),如果第一个字符是d,则表示目录,如果是-,则表示文件。
$ ls -l
total 4
-rw-rw-r-- 1 zjq zjq 4 Aug 12 17:12 INCAR
drwxrwxr-x 2 zjq zjq 6 Aug 12 16:35 python
drwxrwxr-x 2 zjq zjq 6 Aug 12 16:35 vasp
表示INCAR是文件,而vasp和python是目录。如果执行了cd INCAR,则会报错。
-bash: cd: <目录名>: No such file or directory
这是因为你所要进入的目录不存在。请再次检查你所输入的目录是否正确。
-bash: cd: <目录名>: Permission denied
这表明你尝试进入一个你没有权限的目录。例如,在/home目录下,有ljk和zjq两个目录,分别表示两个用户。如果执行ls -l则会发现:
$ ls -l
total 32
drwx------ 13 ljk ljk 4096 Aug 5 17:34 ljk
drwx------ 75 zjq zjq 4096 Aug 12 17:12 zjq
很显然,每个目录只有目录拥有者自己可以访问。例如,作为用户zjq,当尝试执行cd ljk时,则会报错。
这种情况有一个特例:root用户。对于root用户而言,可以进入任何目录。但通常来说,root用户是由服务器管理者所持有的,作为一般用户而言,不需要也不应该进入没有权限的目录,或者执行没有权限的操作。
mkdir: cannot create directory <目录名>: No such file or directory
虽然我们说可以用绝对路径或相对路径在更远的层级关系下创建目录。但这一操作的前提是,这个目录的上一级目录需要存在。例如,当你执行mkdir vasp/lattice/Fe时,首先需要确保目录vasp和vasp/lattice存在,才会创建vasp/lattice/Fe。如果你要创建的目录其上一级目录不存在,则会报错。
一个很自然的解决方法是:一层一层创建。这种方法虽然麻烦,但可以确保目录是清晰的。
如果你确实想要一个快捷的方法,可以使用选项-p。这一选项可以在遇到没有的目录时自动为你创建。例如,上面的例子也可以直接使用mkdir -p vasp/lattice/Fe,但这一操作需要保证输入内容是正确的。一旦有内容输错,则极有可能造成目录结构混乱。
mkdir: missing operand
很显然,你在使用mkdir时没有给任何参数。正如创建目录所说的那样,在调用mkdir时必须提供一个参数表示要创建的目录路径。
1.3 文件操作
作者:Jiaqi Z.
知识点
- 如何移动文件(目录),如何给文件(目录)重命名
- 如何删除文件(目录)
- 如何复制文件(目录)
这一节,我们专注于文件的相关操作。类似于Windows的基本操作,Linux的文件操作也无外乎就是移动、删除、复制。同时,这一节的许多命令对于文件和目录都是适用的,但可能会有一个注意事项,这往往会出错。
移动文件 mv
在Linux当中,移动文件使用的命令是mv。其基本用法是mv <源文件路径> <目标文件路径>。例如,我们在vasp目录下,希望将里面的OUTCAR移动至上一级目录,可以使用mv OUTCAR ..。类似地,对于更复杂的文件移动,只不过在描述路径时稍微复杂一点,其他的步骤没有什么不同。
如果你足够敏感,也许会发现一点问题:为什么前面的命令,OUTCAR是文件,而..是目录?两个难道不应该统一吗?
对于这个问题,可以分两个部分讨论:如果前面是文件,后面也是文件,例如mv OUTCAR ../OUTCAR,这个命令与前面的命令效果是完全等价的。但是,有趣的地方在于,如果你试着执行mv OUTCAR ../INCAR的话,你会发现,Linux将OUTCAR移动到..的同时,还将其改名为INCAR。
进一步想一下,如果我们现在直接写成mv OUTCAR INCAR的话,可以将其看作把当前目录下的OUTCAR移动至当前目录,同时改名为INCAR,总的效果就是,文件被重命名为INCAR。
正如你所见到的那样,Linux没有单独的重命名文件命令,而是通过mv命令来完成。
进一步,如果前后两个参数都是目录会发生什么呢?很简单,就是将前面的目录移动至后面的目录,从效果上看,近似于将第一个参数的目录看作文件。
与文件移动类似的操作,如重命名,对目录的移动同样成立。
如何删除文件 rm
相比于移动文件需要两个参数,删除文件的命令rm只需要一个参数即可,也许你也能猜到这个参数的含义,即rm <删除的文件路径>。例如,要删除当前目录下的INCAR文件,只需要执行rm INCAR即可。同样的,你也可以使用更复杂的绝对路径或相对路径,例如,删除上一级目录下的OUTCAR文件,可以使用rm ../OUTCAR。
与Windows不同,Linux删除文件通常是直接删除,而不是放在所谓的回收站内。因此,在删除文件时务必小心。
在有些版本的Linux(例如Ubuntu)当中,删除的文件被移动至/home/<用户名>/.local/share/Trash/files当中,这个目录起到的临时的回收站功能,但你不应该寄希望于这个功能,而是仔细检查删除文件的正确性,并做好合适的备份。
对于删除目录而言,情况有点特殊,需要使用rm -r命令删除一个目录,此时后面所接参数为目录的路径,例如,删除当前目录下的vasp目录,则可以使用rm -r vasp。
-r选项通常表示递归,例如,在rm -r当中,表示递归删除,从而达到删除一个目录的效果。在删除目录时会连同里面的所有内容都删除掉,因此需要特别小心。
如果担心删除错误的文件,可以在选项中使用-i。rm -i表示在删除时询问是否删除。
对于空目录而言,Linux还提供了一个命令rmdir,其用法为rmdir <目录路径名>,可以删除一个空目录。
如何复制文件 cp
复制文件的命令为cp,其用法与移动文件mv几乎完全一样,无非就是将移动改为复制。简单来说,语法就是cp <源文件路径> <目标文件路径>,类似于移动文件当中所介绍的重命名方法,使用cp命令同样可以做到复制的同时重命名。例如,cp vasp/OUTCAR ../INCAR表示将vasp目录下的OUTCAR文件复制到上一层目录,并重命名为INCAR
如果想要复制一个目录,也需要使用选项cp -r。例如,cp -r vasp/ python/表示将vasp目录复制到当前目录并重命名为python。
我们在上面的命令当中使用vasp/和python/表示两个目录。其中使用了符号/作为结尾,这个符号通常强调该路径是个目录。对于Linux本身而言,有没有这个符号并没有区别。例如,cp -r vasp python也可以表示上面的操作。我们这么写只是为了强调这两个路径是目录而不是文件。
一次性处理多个文件
前面介绍的rm,cp,mv,以及在目录操作一节所介绍的mkdir,都是可以针对多个文件同时操作的。以rm为例,如果想同时删除多个文件,只需要在后面添加多个参数即可,其中参数之间以空格分割。例如,rm INCAR KPOINTS表示删除当前目录下的INCAR文件和KPOINTS文件。对于mkdir创建多个目录而言,也是一样的用法,例如,使用mkdir vasp ML表示在当前目录下创建vasp目录和ML目录。
对于cp和mv而言,情况稍有不同。它们自身就需要两个参数,第一个是源路径,第二个是目标路径。如果有多个文件需要处理,Linux默认最后一个路径为目标路径,前面的所有参数都是源路径。例如,cp INCAR KPOINTS POSCAR POTCAR ..表示将INCAR,KPOINTS,POSCAR和POTCAR复制到上一级目录中。
对于cp和mv而言,若一次性移动多个文件,则最后一个参数必须是目录。这就意味着不能进行重命名操作。
错误处理
rmdir: failed to remove <路径名>: Directory not empty
使用rmdir命令时,只能用来删除空目录。当要删除的目录不是空目录时,执行该命令则会报错。使用rm -r <路径名>往往是删除非空目录的常见方法。
cp: -r not specified; omitting directory <路径名>
当使用cp复制目录时,需要添加-r选项。如果没有添加这一选项则会报错。
cp: target <路径名> is not a directory
这通常出现在尝试使用cp复制多个文件时,最后的参数必须是目录。如果此时不是目录,则会报错。
rm: cannot remove <路径名>: No such file or directory
表明你正在使用rm命令删除一个不存在的文件。请仔细检查你的文件路径名是否正确。
rm: cannot remove <路径名>: Is a directory
类似于cp复制目录,使用rm删除目录时,也需要添加-r选项。特别地,对于一次性删除多个文件,如果在删除文件的同时也存在把目录删除的情况,也需要添加这一选项。
rm: remove write-protected regular file <文件名>?
当你尝试对没有权限(不可写)的文件进行删除时,会提示该错误。关于权限的内容,将在文件权限管理一节详细讨论。在Linux当中,是有方法对文件权限进行修改的,但这并不是一个明智的方法。仔细检查文件操作,遵守这些权限,不要“越界”,可以保证你“安全”地使用操作系统(不会引起系统崩溃等严重问题)。
如果你确实需要删除,则只需要输入y(表示“yes”)并回车即可;反之则输入n(表示“no”)。
1.4 查看文件
作者:Jiaqi Z.
知识点
- Linux文件类型
- 如何查看Linux文件
这一节看似知识点不多,但命令还是挺多的。因此,一节只讲这一部分内容完全足够了。
Linux文件类型
在显示目录文件当中,我们介绍了ls -l命令可以以列表形式查看文件。当时仅仅提到,第一个字符如果是d则表示目录,如果是-则表示普通文件。在这一部分,我们稍微详细介绍一下更多的文件类型。
- 普通文件(
-):就是普通的文件,通常可以分为文本文件,可执行文件和压缩文件等; - 目录(
d):在Linux当中,目录也是一种文件,该文件下存放的是这一目录下的inode号(又名索引节点)和文件名等信息。当执行打开文件时,Linux实际上是通过inode号找到当前文件所在block(8个磁盘扇区组成一个block),从而执行文件; - 设备文件,又分为块设备文件(
b)和字符设备文件(c)。其中前者可以以“块”为单位进行访问(例如硬盘,软盘等),而后者则是以“字节流”的方式访问(例如字符终端、键盘等)。一般来说,设备文件存放在/dev/目录下; - 链接文件(
l):一般情况下指的是符号链接(软链接),类似于Windows操作系统下的“快捷方式”。创建符号链接的方法是使用ln的-s选项1,例如,ln -s INCAR INCAR_link表示创建了一个指向INCAR文件的链接文件INCAR_link。当源文件删除时,符号链接文件也会删除; - 管道文件(
p):通常用于进程间的通信,创建方法是mkfifo命令2,即mkfifo fifo_file。 - 套接字文件(
s):用于通信(尤其是网络上的通信)。简单来说,这是为了避免多个进程或多个TCP连接同时在一个TCP协议端口传输数据造成混淆。一般来说,套接字文件包含目的IP地址,传输层使用协议(TCP或UDP)和使用的端口号,利用套接字文件将三个参数组合起来,从而在传输过程中实现并发服务。
查看文件内容 cat,tac
当然,从文件操作本身来说,第一件事应当是创建文件。但是,创建文件需要的内容较多(例如,需要一些vi编辑器的使用,可能还需要重定向命令,在后面的章节再详细介绍。
如果是初学者,希望可以尽快上手的话,你可以试着在Windows本地用记事本创建一个文本文件,并在里面随意输入一些你喜欢的文字(建议使用英文,对于中文等非ASCII字符而言,可能会出现乱码。),然后利用远程终端将文件发送至服务器(对于MobaXterm而言,在终端左侧有一个目录列表,你可以直接将文件拖拽至相应的目录中;对于其他终端软件,请参考其软件具体的操作方法)。后面对文件的查看操作,都可以对这个文本文件进行。
首先需要了解的是,如何查看完整的文件。在Linux当中,查看文件内容的命令是cat,其基本用法是cat <文件路径名>例如,对于位于当前目录下的INCAR文件,可以使用cat INCAR查看其内容。
cat命令有一些常用选项,例如,可以使用cat -n或cat -b显示行号,二者的区别在于前者会显示所有行号,而后者只对有内容的行显示行号。如果文本中空行内容太多,可以使用cat -s对空行进行压缩,使其缩减为一个空行。
相对地,命令tac也是查看所有内容,只不过它是从最后一行倒着输出。可以看出,tac本身就是命令cat倒着写。例如,tac INCAR表示从最后一行开始输出INCAR文件。
命令cat并不是单词“猫”的意思,而是连接concatenate的缩写。正如单词所表示的那样,cat最原始的功能,是连接多个文件。例如,有一个文件叫a,另一个文件叫b,执行命令cat a b,则会将两个文件内容按照顺序连接起来并输出。
关于文件后缀名
对于熟悉Windows的用户而言,看到上面(包括之前的所有示例)也许都会有一个疑惑:在Linux当中,文件名为什么没有后缀?事实上,后缀名的重要性仅仅是Windows操作系统给你的一个“错觉”,让你误以为后缀名很重要。事实上,Windows操作系统的文件名后缀并不会影响这个文件本身。
虽然表示后缀名的.可以任意放置,但有一个地方比较特殊--文件名开头。对于以.开头的文件名而言,它表示的含义是隐藏文件(这在关于隐藏文件一节介绍过了)
对于Windows操作系统而言,使用后缀名往往是为了决定文件的打开方式(取决于Windows特有的注册表);而Linux文件大多都是文本文件(甚至系统配置也是文本文件),因此在Linux当中,文件后缀名就变得不重要了。也正因如此,在Linux当中你可以类似于Windows后缀名的方式创建任何的后缀(*.jpg,*.xyz甚至*.zjq,*.ykn都是可以的),在Linux看来,它们仅仅是文件名的一部分。
甚至,在Linux当中,大多时候文件都是没有后缀名的。这也就是之前的INCAR和OUTCAR为什么没有后缀。对于从Windows创建的文本文件上传至服务器而言,可能还留有所谓的后缀名*.txt,你完全可以使用mv命令将后缀名删去,丝毫不影响文件本身和其他命令的运行。
按页查看文件 more,less
使用cat和tac查看文件,都是“一股脑”输出到终端里,对于比较短的文件而言,这种方法是可行的;如果这个文件很长,则要上下翻页就会比较繁杂。
对于多页的文件而言,Linux可以使用more命令查看。基本用法是more <文件路径名>。例如,使用more ../band/OUTCAR就可以查看上一级目录下的band目录下的OUTCAR文件。在查看过程中,可以使用空格进行翻页,使用回车进行下一行查看。
在查看过程中,可以随时使用q键退出。
对于一些需要往回翻页查看的文件,可以使用less命令。基本调用格式与more类似,即less <文件路径名>。与more不同的是,less命令可以向上翻页(使用Page Up键或者b键)3。
除次之外,也可以使用d向后翻半页,使用u向前翻半页。
对于more而言,实际上也可以通过b键实现向前翻一页的效果。但相比于less而言,more的自由性并不是太高。而且,使用b向前翻页的效果对于管道文件无法实现。
此外,less还有更复杂的“搜索功能”,例如,可以使用符号/<字符串>的方法实现向下搜索,使用符号?<字符串>的方法实现向上搜索。同时,less的其他命令都是在显示文件后的操作,并不是类似于之前的“选项”(即使用-的形式),这种方法与vi的使用类似。
无论是more还是less,都可以使用q键退出显示文件。
取头部head和取尾部tail
有时,可能会希望仅仅查看一个文件的开头或者结尾。此时可以使用Linux操作系统下的head和tail命令。这两个命令的基本调用方法都是一样的,即head <文件路径名>和tail <文件路径名>。例如,使用head POSCAR就可以查看当前目录下POSCAR文件开头几行,同理,使用tail relax/OSZICAR就可以查看relax目录下的OSZICAR文件结尾几行。
通常情况下,直接调用head和tail得到的都是开头(或结尾)10行的内容。在有些时候,可能会希望输出更多行,或者少输出几行避免混乱。此时可以使用参数-n实现,其基本格式为head -n <行数> <文件路径名>和tail -n <行数> <文件路径名>,这一选项表示输出指定的行数。例如,head -n 5 POSCAR可以查看POSCAR文件开头5行。对于tail同理。
除此之外,head和tail还提供了选项-c,表示输出开头(或结尾)多少个字符的内容,格式与上面-n选项类似,即head -c <字符数> <文件路径名>和tail -c <字符数> <文件路径名>。
错误处理
cat: <文件名>: Is a directory
cat命令仅限于查看文件内容,若后面所接内容为一个目录,例如,cat vasp/则会报错
输入cat命令后忘记输入文件名直接回车,输入文件名后结果只输出了文件名,并没有输出内容
当直接调用cat而没有接任何参数时,表示将终端标准输入所读取到的内容输出到终端。对于普通调用cat <文件路径名>而言,是将读取到的文件输出到终端。若没有任何参数,则会读取后面输入的内容。
退出的方法则是使用ctrl+d键结束当前输入,或者使用ctrl+c键强制终止当前命令。
cat: <文件名>: No such file or directory
文件路径不存在,检查一下路径(尤其是当前工作路径)是否正确。
head(或tail): invalid number of lines: <文件名>
当你使用head -n或tail -n时,后面的行数是必须提供的一个参数。若没有提供行数,则会报错。
head(或tail): cannot open <文件名> for reading: No such file or directory
文件路径不存在,检查一下路径(尤其是当前工作路径)是否正确。
head(或tail): error reading <文件名>: Is a directoryy
类似于使用cat打开目录,使用head或tail打开目录就会报这种错误。
使用more查看文件,输出*** <文件名>: directory ***
这是因为试着用more查看目录而不是文件。
使用less查看文件,输出许多奇怪的路径,不是想要的内容
如果你仔细看一下里面的内容就会发现,当你用less查看目录时,输出的是这个目录下所有的文件和目录(包括隐藏文件)。事实上,使用less <目录路径>得到的结果和使用ls -l <目录路径>是一样的。只不过前者是单独输出的,而后者是直接输出在终端里。
Missing filename ("less --help" for help)
在调用less时忘记提供文件路径了。
more: bad usage Try 'more --help' for more information.
与上面的错误类似,在调用more时忘记提供文件路径了。
1.5 压缩与解压缩
作者:Jiaqi Z.
知识点
- 如何压缩文件
- 如何解压缩文件
备份和压缩
虽然在许多场合,会将Linux的一些使用tar的操作说成是压缩文件和解压缩文件,但这个表述实际上是不贴切的。事实上,tar的本意是tape archive,指的是“磁带存档”,是为将若干个文件归档到磁带上,从而方便备份而设计的。而压缩文件实际上在tar当中经历了另外的步骤,即gzip压缩,或者是bzip2压缩等。这些在命令上都是通过额外的选项实现的。
但是,由于现在大多数时候都是习惯于将两个步骤合二为一,包括使用gzip压缩后得到的.gz文件也可以在Windows操作系统下解压缩,从而极大方便了文件之间的跨系统传输。因此,在通常情况下,我们使用到的都是“压缩”。这里之所以给出两者的不同仅作为补充扩展用,在后续表述中,往往不做区分,一律表述为“压缩”和“解压缩”。
使用tar命令压缩文件
tar命令在使用时通常会配合许多选项,在官方文档中,选项就有50个左右甚至更多,因此,我们不可能在这里完全介绍完所有的选项。对于一般的科研工作而言,只需要掌握几个最基本的选项即可。
首先一个最基本的选项是tar -c,表示创建备份文件。通常仅有这一个参数是不够的,还需要配合以如tar -f参数,这一参数表示指定备份文件。结合这两个选项,可以得到一个备份文件的基本模式为:tar -cf <备份文件路径> <要备份的文件1路径> <要备份的文件2路径> ...。例如,tar -cf vasp.tar INCAR KPOINTS POSCAR POTCAR表示将当前目录下的INCAR,KPOINTS,POTCAR和POSCAR备份至当前目录的vasp.tar当中。
-cf后面的参数,除第一个是备份文件路径外,后面所有参数都是要备份的文件路径。
正如备份和压缩所说的关于压缩和备份的区别一样,我们这里所做的仅仅是备份。对于真正的压缩,我们还需要添加一个压缩格式1。对于常见的gzip压缩格式而言,使用的选项是tar -z。因此,一个完整的压缩命令可以表示为tar -czf <压缩文件路径> <要压缩的文件1路径> <要压缩的文件2路径> ...。
一般情况下,使用gzip压缩的文件后缀名都是.gz。
对于上面所提到的备份例子,你能想到它的压缩命令是什么吗?
答案:tar -czf vasp.tar.gz INCAR KPOINTS POSCAR POTCAR
解压缩
相对地,有了压缩过程,就一定会有解压缩过程。首先,先忽略掉压缩格式(即gzip等相关内容),仅仅从备份的角度,考虑它的逆过程,也就是还原文件。
在tar当中,可以使用选项tar -x实现备份文件的还原。例如,在开始的备份操作中,可以使用tar -xf vasp.tar实现对备份文件vasp.tar的还原。对于解压缩过程,选项完全类似,只需要使用tar -xzf即可。例如,对上面的vasp.tar.gz进行解压缩,可以使用tar -xzf vasp.tar.gz。
查看压缩文件
这里所说的查看压缩文件,主要指的是查看压缩包内的文件,从更广义的角度看,就是查看所谓的“备份”文件。
首先,在tar里面有一个选项tar -v,可以在压缩(解压)过程中查看压缩(解压)的文件。例如,上面的压缩和解压命令,分别可以写成tar -cvf vasp.tar INCAR KPOINTS POSCAR POTCAR和tar -xvf vasp.tar。对于gzip格式的压缩和解压缩,只需要在参数里额外添加-z即可。
在使用tar -t时,往往需要配合以-f参数指定压缩文件名。其完整用法为tar -tf <压缩文件路径>。例如,使用tar -tf vasp.tar可以查看vasp.tar压缩文件中的文件列表。
无论是普通的备份文件,还是使用gzip压缩的文件,都是使用tar -tf查看(没有选项-z)。
使用tar -tvf同样可以得到文件列表,只是输出的内容更详细(类似于ls -l的输出结果)
除此之外,查看压缩文件还有一种方法,使用less命令。通过less <压缩文件路径>可以直接查看压缩文件内容,其形式上类似于tar -tvf和ls -l。
压缩文件的追加与合并
虽然已经非常小心地创建了压缩文件,但有时还是会有遗漏。例如,当你将INCAR,POSCAR,KPOINTS和POTCAR已经添加到vasp.tar之后,突然发现还应当把CONTCAR添加进去。如果此时文件还保留着,当然,重新使用tar -cf vasp.tar ...也是可以的(其中...表示五个文件路径)。但是,如果之前的文件已经删除了呢?解压后再重新压缩也不是不可行,但总是麻烦一步。
在tar的选项中,提供了一个选项tar -r表示将文件追加到压缩文件内。例如,上面的例子,可以直接使用tar -rf vasp.tar CONTCAR即可将CONTCAR添加到vasp.tar中(哪怕原先的四个原始文件删除了也没关系)。
上面的例子是将文件追加到压缩文件内,如果是将压缩文件内的所有文件全部追加到另一个压缩文件里呢?可以使用tar -A选项。其格式为tar -Af <追加的目标压缩文件路径> <追加的压缩文件路径>。例如,我们已经有了包含INCAR,KPOINTS,POSCAR,POTCAR的压缩文件vasp.tar,此时又有一个压缩文件result.tar,里面包含有OUTCAR,CONTCAR,如何将其合并到共同的vasp.tar当中呢?可以使用tar -Af vasp.tar result.tar。
这里的选项-A是大写字母,千万不要写成小写字母。二者的含义不同,对于小写字母tar -a,表示根据后缀来决定压缩格式。例如,使用tar -caf vasp.tar.gz INCAR将会以gzip格式创建压缩文件。
同时,使用-A合并压缩文件时,只能对两个文件进行合并。
错误处理
tar: <压缩文件路径>: Cannot stat: No such file or directory \\tar: Exiting with failure status due to previous errors
通常这是因为在调用tar时错误放置了压缩文件路径和被压缩的文件路径的位置。在使用tar进行压缩时,第一个参数是压缩文件路径,第二个参数是被压缩的文件路径。
例如,对前面的例子,如果使用的是tar -czvf INCAR KPOINTS POSCAR POTCAR vasp.tar.gz,就会报错。
tar: Refusing to write archive contents to terminal (missing -f option?) \\tar: Error is not recoverable: exiting now
在使用tar进行压缩(或解压)时,需要给定选项-f并指定压缩文件名,例如tar -cf vasp.tar INCAR。如果没有选项-f则会报错。
tar: Cowardly refusing to create an empty archive
这意味着你在压缩文件时试图压缩空的文件。这通常是因为你没有指定压缩文件(例如,直接调用tar -cf vasp.tar就会报错)。
还有一种可能是你错用了压缩选项-c和解压缩选项-x。例如,也许上面的命令你是想解压vasp.tar,那么你需要的命令是tar -xf vasp.tar。
tar: <压缩文件路径>: file is the archive; not dumped
这可能是因为你在压缩文件时对压缩文件本身进行压缩,这可能会造成递归压缩。例如,tar -cf vasp.tar vasp.tar时就会报错。
但是,压缩文件本身是可以被压缩的。例如,tar -cf vasp.tar result.tar是允许的,这执行的操作是将result.tar文件压缩至压缩包vasp.tar当中。
1.6 文件权限管理
作者:Jiaqi Z.
知识点
- 用户、用户组和其他用户
- 如何查看文件权限
- 如何修改文件权限
用户和用户组
Linux是一个多用户操作系统,因此,如何管理不同用户就成为一个至关重要的话题。例如,在科研过程中,同一课题组的多个成员可能会使用同一个服务器,此时每一个成员就是Linux当中的用户。每一个用户通常都有一个主目录,通常为/home/下的目录1。
在显示目录文件当中介绍过如何使用ls -l查看一个文件的完整信息,其中提到了用户组的概念。顾名思义,用户组就是用户的组合。举一个例子:如果我们把你家庭的房子看作一个Linux操作系统的话,那么你的家人和你就组成一个用户组。而每一个人就是一个用户。对于家庭的共有物品而言(例如空调、冰箱等)是所有家人可以共同使用的,即对整个用户组可用;而相对地,你的房间,你的柜子可能只是你自己可以打开,此时我们说只对某一特定用户可用。
相对地,对于不是你家庭成员的其他人(比如你的邻居等),他们是属于其他用户组的用户,对于你家的所有东西都不可用。
上面的例子也许你还看得“一头雾水”,什么可用、不可用,到底有什么用。事实上,用户组的应用场景大多集中在关于权限的操作上。而这件事则是下一部分的内容。
同时,前面提到的所有用户中有一个特殊用户--root用户。对于他而言,拥有最高的权限和能力,即可以进入任何地方。也正如在前面多次提到的那样,对于一般科研工作而言,不需要了解root的相关内容。因此在这里,我们就将其略过去了。
文件权限
前面介绍ls -l命令时已经说明了一些关于文件权限的内容,现在来进一步介绍如何查看文件权限,以及如何理解文件权限的含义。
与前面所介绍的一样,文件权限可以利用ls -l或者ll查看。通常来说,每一个文件(包括目录)的第一组字符串表示了文件类型和参考文献。其中文件类型的相关内容已经在Linux文件类型当中介绍过了,现在我们重点关注后面九个字符,即文件权限。
以/bin目录下的cd文件为例2,使用命令ls -l /bin/cd可以得到如下结果
$ ls -l cd
-rwxr-xr-x. 1 root root 26 Oct 9 2021 cd
输出结果的第一个部分就是文件权限。其中第一个字符-表示这个文件是一个普通文件,后面的9个字符,每三个一组,分别表示拥有者,所属用户组和其他用户的权限。例如,对于cd文件为例,拥有者(即输出结果的第三部分root)的权限是rwx;而所属用户组(输出结果的第四部分root)具有r和x的权限;同样,对于其他用户来说,也是具有r和x权限。
在这里你见到了ls -l的新用法,即在后面添加一个文件的路径。即ls -l <文件路径>,可以查看该文件的属性。
同时,也许你注意到上面的第一部分输出结果还有一个.,这表明该文件是在SELinux模式下创建的。其中SELinux叫做安全增强型Linux(Security-Enhanced Linux),其目的在于最大限度地减小系统中服务进程可访问的资源3。对于使用SELinux模式创建的文件,在权限后面会有.作为标志(如同上面的cd命令一样)。
在文件权限中,每种用户又包含有可读权限(r),可写权限(w)和可执行权限(x)。可读权限表明用户可以读取文件内容,对于目录而言表示用户可以查看目录内文件;可写权限表明用户可以修改文件内容,对于目录表示用户可以移动、删除目录内文件;可执行文件表明用户可以执行文件(一般为脚本文件或其他程序),对于目录表明用户可以进入目录。
每种用户的权限一共就这三种,且数量和顺序都是固定的(即rwx);对于没有的权限,使用短横线-表示无该权限。例如,r-x表示可读可执行,但不可写(如同上面的/bin/cd一样)。
考虑一个很简单的例子:如果一个文件的权限表示为-rw-rw-r--,对其他用户而言,含义是什么呢?
答案:该文件对其他用户而言只读。
修改文件权限 chmod
在Linux当中,可以使用chmod修改文件的权限。修改方式有2种,第一种是直接设定三种用户的所有权限(共9位)。但是,如果直接写类似于rw-rw-r--这样子的形式的话,就稍显繁琐。如果考虑到特定的位数,可以把这三个权限的开关看作二进制的“0”和“1”,其中拥有权限为“1”。这样子就可以通过1个十进制数字表示一种用户的权限。例如,对于r--,可以将其写作100也就是十进制的4;类似地,对于r-x,可以写作101也就是5。
关于进制转换,对于任意一个$p$进制数,其中表示在范围内的数,将其转化为十进制的方法是
例如,对于二进制数101,转化为十进制可以算作。对于十进制转二进制,可以使用短除法进行,具体可以参考网站短除法。
在有些专业教材中,可能会使用0b表示二进制数,例如0b101,其中b为二进制单词binary的缩写。
使用这种数字表示方法修改权限的格式为chmod <权限> <文件路径>。例如,对supercell文件执行chmod 755 supercell则表示最终的权限为rwxr-xr-x。
思考一下,如果想让一个目录只对所有者提供全部权限,而其他人无权限,用数字表示应当怎么写?
答案:700表示rwx------
虽然这种方法可以修改所有权限,但有时我们仅仅希望添加或删除某一特定的权限。例如,当我们编写了一个程序后,可能只希望给它添加一个对所有者的可执行权限,甚至不关心它对其他用户的权限如何,如果再一点点算,就有点麻烦。例如,原本的权限是rw-r--r--,诚然使用chmod 744 <文件路径名>可以实现这一功能,但有没有更简单的方法呢?
在chmod命令中,除了使用数字表示权限外,还可以利用如+, -和=这样的符号进行增添、删除或修改权限。其基本用法为chmod [用户]<操作符><权限> <文件路径>。其中[用户]表示想给所有者(u),所属用户组(g)还是其他用户(o)修改权限。对于操作符而言,+, -和=分别表示增加权限、删除权限和更改权限。后面的<权限>使用r, w, x这种表示方法。
举个例子,如果我们希望给文件所有者添加一个可执行权限,则可以直接执行chmod u+x <文件路径>即可;如果希望给其他人删除可读权限,则使用chmod o-r <文件路径>。如果希望给所有者和所属组设置为可读写权限的话,可以用chmod ug=rw <文件路径>。
正如后面的例子所展示的那样,[用户]和<权限>都可以一次性写多个。当然,有时可能会希望一次性给所有用户设置权限,例如给所有人可读写权限,在chmod当中,对于[用户]还提供了一个选项a,表示所有人。例如,chmod a=rw <文件路径>表示设置为所有人可读写。
同时,利用这种方法也可以设置不同的权限,即一次性设置多个用户,其中用,分隔。例如,如果希望将权限设置为rwxrw-r--,则可以直接写作chmod u=rwx,g=rw-,o=r-- <文件路径>
错误处理
希望给文件所有者自己设置权限,使用数字之后为什么给其他用户设置权限了,而所有者没有权限
在使用数字表示的时候,三位分别表示所有者、所属组和其他用户。对于不足三位的数字,其前面默认补零,例如,chmod 7 <文件路径>实际上等价于chmod 007 <文件路径>
对于稍微了解计算机的读者来说,也许你已经有所察觉了。我们之前说这个数字是十进制数字,但严格来说,它是八进制数字。对于八进制而言,它的每一个数位上的数字,都与3位二进制对应。例如,八进制的7表示二进制的111,八进制的3表示二进制的011等。具体转换如表十进制,二进制和八进制对应表所示。
| 十进制 | 二进制 | 八进制 | 十进制 | 二进制 | 八进制 |
|---|---|---|---|---|---|
| 0 | 000 | 0 | 4 | 100 | 4 |
| 1 | 001 | 1 | 5 | 101 | 5 |
| 2 | 010 | 2 | 6 | 110 | 6 |
| 3 | 011 | 3 | 7 | 111 | 7 |
在一些专业的计算机书籍或其他地方,八进制会用0o作为前缀(其中第一个是数字0,第二个是小写字母o)。例如,0o5=0b101=5。当然,因为八进制每一个数位的范围0到7小于十进制0到10的区间,因此对于7以内的数字而言,八进制和十进制是一样的。但随着数字增加,二者会出现差别,但八进制和二进制之间仍存在一一对应关系。例如,23=0b010111=0o27。
事实上,每三位二进制的对应关系产生了八进制,而目前更常用的是四位二进制对应关系所产生的十六进制(前缀为0x)。
2.1 使用nano简单创建文件
作者: Jiaqi Z.
知识点
- 如何使用
nano创建并编辑文本文件
在Linux命令行操作一章当中,已经了解了如何对Linux进行基本的操作,例如查看目录、移动或删除文件等,同时在文件权限管理一节讨论了如何给文件添加权限,例如,给脚本程序添加可执行权限。
然而,我们在Linux的所有对文件的操作,目前只限于读取,对于编辑,目前所采用的方法是将其保存至Windows下,利用记事本等软件进行编辑,完成后再上传回Linux系统。然而,无论是使用Linux本地操作系统,还是在服务器上使用,如果可以在系统中直接编辑文件,显然更方便1。在本章,我们将详细介绍Linux下如何编辑文件。
目前,Linux最常用的文本编辑器是vi和vim,而在这之前,我们先介绍一个更简单的文本编辑器--nano。相比于vi和vim,nano功能可能会更少,但是作为开始Linux文件编辑的第一步,也许是合适的。
在很多时候,我们会把vi和vim放在一起讨论。它们具有类似的界面,类似的工作模式,因此很多人容易将其混为一谈。实际上,vi是由Bill Joy在1976开发的一款Unix操作系统下的可视化编辑器(Linux是1991年诞生的);而vim是Bram Moolenaar在1991年开发的vi改进版(Vi improved),其功能包含语法高亮、插件支持等。
虽然我们经常在Linux当中使用vim,但它本身是可以跨平台运行的,如Windows本身也是可以安装支持vim。只不过由于Windows本身的文本编辑软件足够丰富,同时大多数Windows用户并不熟悉命令行操作本身。因此,很多人也是在接触Linux的时候第一次接触vim编辑器。
关于二者之间的更多区别,可以查看网址:Linux中的vi与vim:编辑器的王者之争与深度探索
使用nano创建第一个文件
使用nano命令非常简单,通常只需要使用nano <要打开的文件路径名<,对于不存在的文件,它会自动创建一个;而已经存在的文件则会将其打开。
例如,在家目录下,我们直接创建一个名为hello的文件。使用命令nano hello,则会进入nano编辑器的模式。如果你用过老式操作系统,则会发现这个界面十分“复古”--上面是编辑区,下面是一些选项(类似于Windows软件的“菜单”)如图所示。
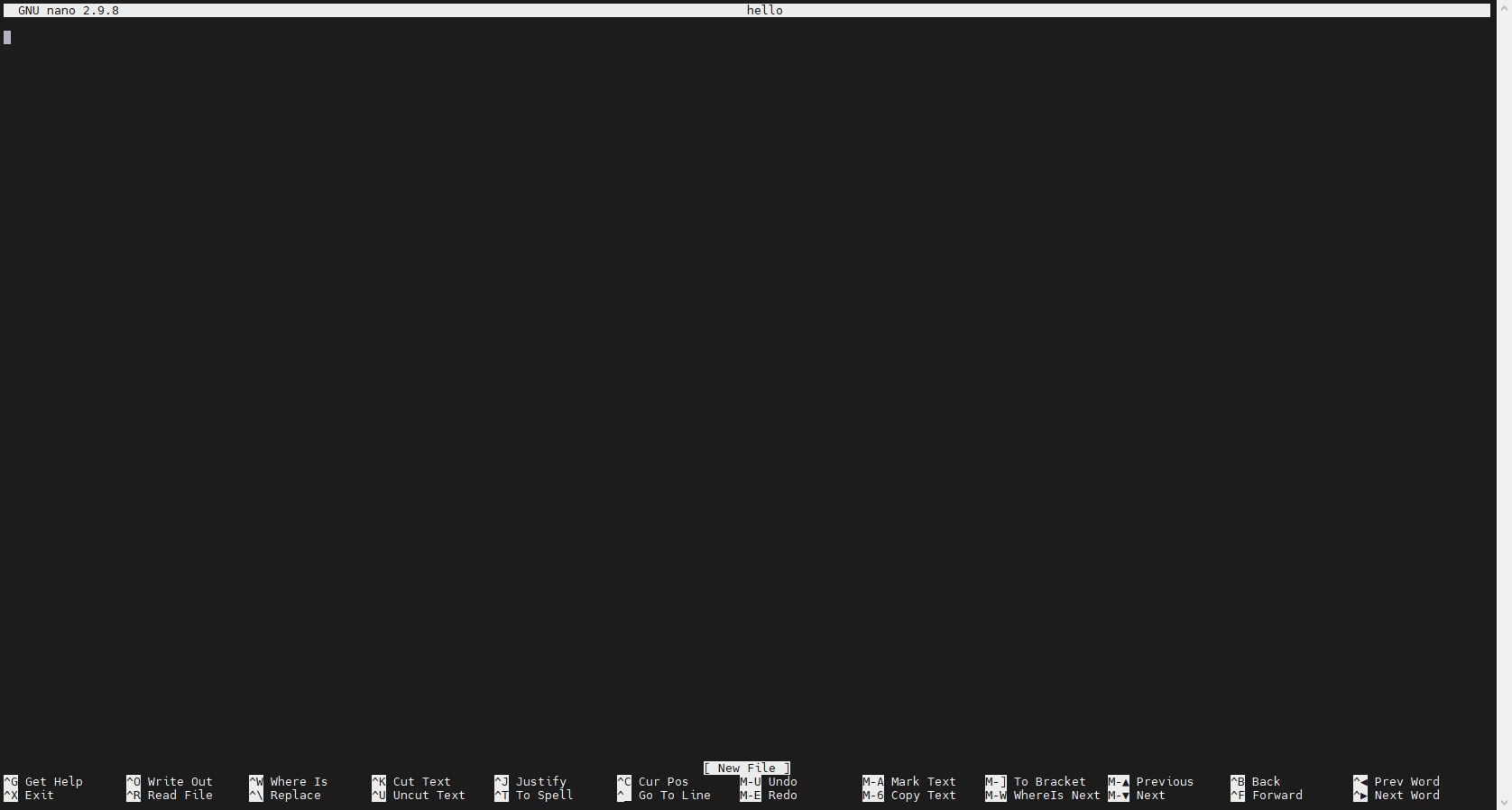
当打开时,软件默认就是编辑模式,你可以在里面随意输入一些内容,例如,输入“hello world”,屏幕上就是直接显示你的内容。对于删除和换行,其操作就如图在Windows下的记事本一样(使用键盘上下左右、删除键等)。重点是下面的菜单选项。难度本身也不大,只需要记住两个符号所表示的含义即可:^表示键盘上的Ctrl键,而M-表示键盘上的Alt键。因此,正如你所看到的那样,在nano当中,使用Ctrl+X退出;使用Ctrl+O保存。
在nano当中,一个很特殊的地方在于它的复制、剪切和粘贴与我们所熟悉的快捷键不一样。根据下面的说明,可以看到,复制是Alt+6,剪切是Ctrl+K,而粘贴是Ctrl+U。
同时,无论是复制还是剪切,默认都是对行进行操作。也可以使用Alt+A2,并用方向键选中文本,进行操作。
此外,nano也支持撤销(Alt+U)和恢复(Alt+E)。
使用nano进行查找和替换
几乎所有的文本编辑器,都需要有一些如查找查找和替换的功能方便我们进行编辑。在nano当中,查找的命令是Ctrl+W,此时下方会弹出一个输入框,输入要查找的内容,回车后光标便会定位在光标下方第一个匹配的开头位置。使用Alt+↓和Alt+↑可以切换到下一个匹配位置或上一个匹配位置。
nano在匹配查找时不区分大小写,例如,想查找SIGMA时,在输入查找内容时输入sigma同样可以。
对于替换功能,其命令为Ctrl+\,此时首先弹出对话框,输入要查找的内容的,之后弹出的对话框输入要替换的内容。之后光标会从当前位置开始向后搜索,当查找到一个后会定位到此处并询问是否替换。输入y表示确认,输入n表示不替换此处。如果确认要全部替换的话,可以直接输入a;相对地,如果发现有错(例如要查找的词语或要替换的词语拼写错了),可以输入c取消替换命令。
除此之外,还有更多的命令(例如查看字数是Alt+D),可以直接使用Ctrl+G查看帮助文档。在帮助文档中还包含有一些命令的快捷方式,例如查看文档除了可以使用Ctrl+G外,也可以直接使用F1键。
nano的使用方法看似讲了很多,实际上只需要记住:^表示键盘上的Ctrl键,而M-表示键盘上的Alt键,其他的,都可以通过下方的说明,或者帮助文档找到。
错误处理
[ File <文件名> is unwritable ]
这是因为你没有这个文件的可编辑权限。借助于修改文件权限一节所介绍的chmod命令可以添加可编辑权限。
[ Error reading <文件名>: Permission denied ]
这是因为你没有这个文件的可读权限,解决方法与上一个错误一样(使用chmod命令)
与前面的注意内容一样,遵守这个权限往往是最正确的选择。
2.2 使用vi,vim创建文件
作者: Jiaqi Z.
知识点
- 如何通过
vi,vim创建并保存文件 - 如何通过
vi,vim打开已有文件
通过vi创建文件
从本节开始,这一章就要开始讨论vi和vim的操作方法。类似于使用nano编辑文件,在Linux当中通过vi(vim)创建文件的方法是vi <文件名>或vim <文件名>。通常来说,使用vi创建文件后的界面如图所示。

正如使用nano简单创建文件开头所说的那样,相比于vi,vim的功能更加强大。目前在很多操作系统当中,都是使用vim代替vi。因此,在本节标题中,我们使用vi和vim作为区分,在后面的讨论中,可能为了方便,我们使用vi代替vim(二者操作方法基本一致)。
如果你确实想知道使用vi命令打开的是vim编辑器还是vi编辑器,可以使用alias命令,在输出中如果看到有alias vi='vim',那么说明实际上你所打开的是vim编辑器;如果没有,则意味着打开的是vi。此时如果希望打开vim编辑器,则需要使用命令vim代替vi。
vi编辑器的三种模式
与nano界面相比,vi界面显得更加“简洁”(没有了下方的菜单栏)。但是,如果你尝试着往里面输入内容的话,会发现往往不会是你想要的结果(也有可能“误打误撞”可以输入进去)。这是因为,在vi当中存在三种工作模式:
普通模式
当你使用vi命令打开编辑器后,则进入了编辑器的普通模式。在这一模式下,你可以使用方向键移动光标,也可以进行删除、剪切、粘贴等简单操作。
一些简单的操作是使用x键删除当前光标所在字符,使用dd删除当前行(实际上是“剪切”),yy复制当前行;使用p(小写)将剪贴板内容粘贴到光标下方,P大写表示粘贴到光标上方。u表示撤销,Ctrl+r表示恢复撤销。
上面这些操作都是比较基础简单的,通常是用于对文件进行修改的。而对于新创建的文件,则可以使用i进入到“编辑模式”。同时,使用a可以在光标下一个位置开始“编辑模式”,o(小写字母)和O(大写字母)分别表示在当前行下方和上方插入新的一行,并进入“编辑模式”
编辑模式
这是最熟悉的模式。可以在这一模式下如同正常文本编辑器一般进行编辑(例如,方向键移动光标,编辑字符,删除键等都是可用的)。除此之外,还有一些快捷键需要介绍一下1这些快捷键很多在Windows当中也有,但可能大多数人并不熟悉。
使用键盘上的Home键和End键可以将光标定位到行首和行尾;使用Page Up和Page Down可以上下翻页;使用Insert可以在“插入模式”和“替换模式”下切换。
在“编辑模式”下使用键盘上的Esc键可以返回到“普通模式”。
命令行模式
这一模式将会是最复杂的,许多vi的高级操作都是基于一系列的命令完成的。进入命令行模式的方法是在“普通模式”下输入键盘上的:。
虽然大多数命令要在后面的章节提到它们,但一些必要的命令还是需要现在知道的--它们涉及到文件的保存和编辑器的关闭。例如,:w表示保存文件,:q表示关闭编辑器,:q!表示强制退出(不保存),而:wq表示保存后退出2。
通过vi打开已有文件
类似于使用nano <文件路径>的方法,使用vi打开已有文件的方法是vi <文件路径>。与前面所介绍的内容一样,打开后的vi界面默认是“普通模式”,此时可以使用一些简单的方式(如dd删除整行等)对文件进行简单的编辑,或者可以使用“编辑模式”进行修改操作。
在修改文件时,请确保是否有修改文件的权限。对于没有权限的文件进行修改,在退出时将会返回“'readonly' option is set (add ! to override)”的错误。
正如错误中所说的那样,你可以使用w!的方式强行覆盖文件,但这始终是一种“下策”。
错误处理
E37: No write since last change (add ! to override)
这表明你在:q退出时文件发生了修改。类似于WIndows操作系统下退出时询问是否保存一样,你需要选择是否保存你的编辑。如果保存,则需要先执行:w再:q,或者直接执行:wq;相对地,如果你不需要保存,则执行:q!强制退出。
W10: Warning: Changing a readonly file
这是一个警告信息,说明你正在编辑一个对你而言有权限限制的文件(大多数时候是“只读”文件,但对于某些“不可读”文件,如果强行编辑,可能也会引起该错误)。如果无视编辑并保存的话,通常会引发下面的错误:
E45: 'readonly' option is set (add ! to override)
这是正文最后所提到的错误,说明你编辑了一个有权限限制的文件。使用:w!可以强行覆盖保存文件,但这并不是一个正确的方法(至少是不推荐的方法)。
[Permission Denied]
这是因为你在查看一个不可读的文件。当你尝试编辑时,则会引发上面的警告或错误。
2.3 查找与替换
作者: Jiaqi Z.
知识点
- 使用
vi的/和?进行字符串查找 - 使用
vi进行字符串的替换
对于一个现代文本编辑器,一个最基本的功能就是对某一特定的字符串进行查找,以及将其替换为另一字符串。相比于其他在Windows操作系统中常见的文本编辑器(无论是记事本、word、还是VS Code等),Linux的vi编辑器下的查找和替换都显得更加复杂。这确实可能带来了一些学习上的困难,但随着使用场景逐渐复杂,你会发现这种代码式的操作的便利性。
查找
首先先来了解如何对一个字符串进行查找。在vi当中,查找的方法是使用/或者?,其基本格式为/[要查找的字符串]或者?[要查找的字符串]。例如,在当前文件中查找Hello,可以输入/Hello,然后回车。
在输入字符串时,vi会同时在文本内将所有匹配的字符串进行高亮(即便没有按回车)。
/和?的作用都是查找字符串,二者的区别在于,/是从当前光标开始向后查找,而?是向前查找。当输入完成后,点击回车,光标会自动定位到最近的相应位置。若要切换,则可以使用n查找下一个或者使用N查找上一个。
替换
相比于查找命令,vi中的替换命令就显得更加复杂了。最基本的命令是s,但通常会配以更多的命令(类似于参数)。一般来说,替换命令可以用下面的方式表示::<开始行号>,<结束行号>s[分隔符][要替换的字符串][分隔符][替换为的字符串][分隔符]<g>。其中<开始行号>和<结束行号>都是可选的,若省略则表示只对当前行进行替换。命令结尾的<g>也是可选的,表示对所有进行替换,若省略则只替换第一个(每一行或当前行,取决于是否有行号)。
同时,在替换时需要使用[分隔符]对字符串进行分割,通常情况下习惯于使用/表示,但在一些特殊的情况下(例如要替换的字符串内带有这一字符),则可能会将其改为其他分隔符。命令当中所有出现分隔符的地方都需要\emph{统一}。
下面是一些例子,例如,若希望将当前行的第一个“hello”替换为“bye”,则需要命令:s/hello/bye/,若希望对所有字符串进行替换,则使用:s/hello/bye/g。
若希望对第一行到第三行的所有“hello”进行替换,则使用:1,3s/hello/bye/g,若没有最后的g,则表示仅对第一行到第三行每一行里面的第一个字符串进行替换。
如果希望对第一行到最后一行的所有“hello”进行替换,则使用:1,$s/hello/bye/g。其中,$表示最后一行。
在vi当中,数字可以具有重复若干次的含义。例如,在前面所介绍的x表示删除当前光标所在字符,若前面加上一个数字,则表示重复这一操作多少次(即删除多少字符),例如,10x表示删除10个字符。
同时,在vi当中,往往使用$表示最后的意思。例如,在普通模式下直接输入$则直接跳转到这一行最后一个字符,类似的,输入0则跳转到这一行第一个字符。输入:$可以直接跳转到文件最后一行。
错误处理
查找(替换)完之后字符串总是高亮显示,怎么将其关闭
使用:noh命令。
E488: Trailing characters
这可能是在输入命令时使用了错误的格式。请仔细检查使用的命令(尤其是替换命令)的格式。
想要替换,却发现把光标上的字符删除了
这是因为在使用替换命令时,前面需要有冒号:。若没有添加这一符号,直接使用s则意味着删除当前字符并插入。
2.4 初窥正则表达式
作者: Jiaqi Z.
知识点
- 什么是正则表达式
- 如何使用简单的正则表达式进行查找和替换
关于正则表达式
在查找与替换一节当中,我们提到过,vi的查找和替换相比于其他文本编辑器都稍显复杂。而这一节所介绍的正则表达式,则是其十分强大的功能之一。
简单来说,正则表达式是一种用于匹配和操作文本的强大工具,它是由一系列字符和特殊字符组成的模式,用于描述要匹配的文本模式。借助于正则表达式,我们可以很方便对许多具有相同模式的字符串进行匹配与处理。例如,对于ENCUT=200和ENCUT=400,从字符串本身来看是不同的,但二者具有相同的模式(ENCUT=加上一系列整数字符)。因此,可以使用正则表达式进行批量处理。
在Linux当中,正则表达式是相对比较复杂的内容。在这一节只是简单介绍一下基本用法,对于更完整的内容,将在后面章节进行介绍。
元字符
正则表达式最有特色的部分,就是可以使用元字符来匹配一系列特定的字符。在介绍一些复杂的元字符之前,先熟悉一个最简单的符号,[],在中括号里面,可以放入一些字符。正则表达式将会匹配这些字符当中的一个。例如,对于字符串“hello”,使用正则表达式[aeiou]就可以匹配到字符串里面的所有元音字母。
在vi当中,可以使用正常的查找方式和替换方式,只不过需要在输入查找的内容时使用正则表达式。简单说,你可以将正则表达式看作是一个表达多个字符串集合的方式,而可以使用这种方式一次性对这个集合内的每一个元素进行查找和替换。这样的话,其使用方法就与普通的查找和替换基本无异了。
同时,特别需要注意的一点是,在vi当中,有一些符号(后面会提到)与Linux本身的正则表达式不同(Linux的命令行本身也是支持正则表达式的),通常区别在于是否添加一个反斜杠(\)。后面遇到时会特别指出。
在上面的例子中,我们可以直接在vi当中直接使用/[aeiou]实现对所有元音字母的查找。
在使用[]时,可以使用-对特定范围内的字符进行查找。例如,使用[a-h]表示对a到h之间的所有字母(小写字母)进行查找。常用的还有,使用[A-Z]表示对所有大写字母进行匹配,[a-z]表示对小写字母进行匹配,[0-9]表示对所有阿拉伯数字进行匹配。
也许你会有疑问:这个范围是按照什么排序的?在计算机当中,这些字符都是根据ASCII码将其转化为二进制存储在计算机内。因此,这里的排序也是根据每一个字符所对应的ASCII码排序的。
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语,而其扩展版本延伸美国标准信息交换码则可以部分支持其他西欧语言,并等同于国际标准ISO/IEC 646。
ASCII 由电报码发展而来。第一版标准发布于1963年 ,1967年经历了一次主要修订,最后一次更新则是在1986年,至今为止共定义了128个字符;其中33个字符无法显示(一些终端提供了扩展,使得这些字符可显示为诸如笑脸、扑克牌花式等8-bit符号),且这33个字符多数都已是陈废的控制字符。控制字符的用途主要是用来操控已经处理过的文字。在33个字符之外的是95个可显示的字符。
例如,0的ASCII码为48,A的ASCII码为65,而a的ASCII码为97。因此,可以使用[0-a]匹配到大写字母A。
同时,中括号里面的字符是可以组合使用的,例如,可以使用[A-Za-z]表示所有的字母。那如果希望表达所有的字母和数字呢?
[A-Za-z0-9]
除此之外,对于一些常见的字符,为其设置了特殊的符号,例如,\d就表示所有的数字字符,\w表示所有的字母、数字和下划线,也就等价于[A-Za-z0-9_]。
而在使用中括号时,也可以使用符号^进行反选。例如,使用^[A-Z]表示排除所有大写字母的字符。
总结
本节简单介绍了一些常见的元字符,并可以将其用于查找和替换。例如,在本节开头所介绍的ENCUT=200和ENCUT=400,使用正则表达式可以直接表示为:ENCUT=\d\d\d1。
正如最开始所说的那样,正则表达式的功能远不止此,对于更复杂的部分(例如,目前使用[]只能匹配一个字符,如何匹配多个字符?),将在后面的章节进行更加详细的介绍。
错误处理
如何查找如[hello]这样的字符串?
在正则表达式当中,已经将中括号作为特殊符号使用。因此,如果想查找带有中括号的字符串,则需要将中括号前面添加一个反斜杠\表示中括号这一字符本身。例如,对于上面的例子,如果直接使用[hello]表示匹配这5个字母(实际为4个)当中的任意一个字符;而使用\[hello\]或者\[hello]都可以表示字符串“[hello]”
3.1 通配符
作者: Jiaqi Z.
知识点
- 什么是通配符
- 如何使用通配符批量处理文件
在Linux命令行操作一章当中,我们介绍了如何使用Linux的命令行进行简单的操作,如查看文件、对文件和目录进行操作等。同时,在文本编辑工具vi和vim一章,我们详细介绍了如何使用vi对文本文件进行编辑。对于绝大多数情况,以上两个章节的内容足够后续的计算任务了。
但“人的本性终究是懒惰的”,在大多数时候,我们可能不希望打开vi后再使用/这样的命令来查找,而是希望直接在命令行查找我们需要的内容。进一步的,对于更多的文件,有时我们希望同时对这些文件的相同内容进行查找,这时在vi中操作就显得麻烦了。因此,在本章,我们会进一步讨论一些在命令行当中的“进阶操作”,主要是为了能够更方便的处理文件和数据。
关于通配符*, ?
通配符是一种特殊语句,主要有星号(*)和问号(?),用来模糊搜索。例如,当查找文件时,如果不知道真正的字符,或者希望匹配一系列具有相似模式的文件时,可以使用它来代替一个或多个真正字符。
其中,*表示零个或多个任意字符。例如,使用*.txt表示文件名最后为.txt的所有文件,可以是hello.txt, bye.txt, roselia.txt等。
上面的例子实际上就是后缀名的表示方法。它并不是一个很新奇的事情,事实上,在Windows操作系统中,当你在打开或者保存文件时,都可以在下面的“文件类型”中看到这种使用通配符的表示方法(如图所示)
同时,如果你“思维敏捷”的话,可能会联想到初窥正则表达式一节所介绍的正则表达式。事实上,通配符在某种程度上也是正则表达式当中的一个特例。

相对地,?表示零个或一个任意字符,例如,he*o可以匹配到hello,而he?o却不能(可以匹配到helo)
使用通配符进行文件目录操作
下面将会简单展示一下,如何使用通配符对文件进行“批量操作”。首先,一个最常见的例子是:批量删除文件。例如,假设当前目录下有data1.dat和data2.dat这样两个后缀名为.dat的文件,如果希望同时删除它们,按照原来的做法,则可能需要按照顺序执行两遍命令:rm data1.dat和rm data2.dat。而借助于通配符,可以只使用rm *.dat表示删除所有后缀名为.dat的文件。
在这一行命令里,通配符所表示的文件可以将其“展开”,等价于rm data1.dat data2.dat。
另外,在命令行当中,通配符的优先级比较高,因此,如果一个文件本身含有符号*,则需要使用反斜线(\)进行转义,例如,rm *表示删除当前目录下文件名为*的文件。相反,使用rm *表示删除当前目录下所有文件(务必要小心这一命令)
同样,使用这一方法也可以批量复制文件,与删除类似,可以使用如cp *.dat data这样的命令将所有后缀名为.dat的文件复制到data目录下。
正如前面所说的那样,这一命令可以将其展开成cp data1.dat data2.dat data
同样,上面对文件名的通配符使用也可以用于目录当中,例如,rm */*.dat表示删除当前目录下的子目录当中所有后缀名为.dat的文件。
*虽然可以表示零个或多个任意字符,但却不能表示目录下的目录。例如,rm */data可以匹配到1/data, 2/data但无法匹配到1/1/data这样更深一级的目录。
关于使用?通配符的使用方法,其基本原理和使用*类似,这里不再举例。同时,你也应该意识到的是,上面的例子中,我们都是把通配符放在了开头或者结尾。不一定总是这样的,例如,完全可以使用如hello*.txt这样的方式表示如hello.txt, hello1.txt这样子的文件。
虽然这一套教程是关于Linux的,但在Windows当中,通配符同样十分强大。与我们通常使用Windows的方式不同,它通常是在命令提示符(cmd)当中使用的。如果你希望在Windows当中体验这一功能,可以在开始菜单搜索cmd(对于新版Windows操作系统也可以是更高级的PowerShell)。
一些基本的操作语法与Linux类似,但有些操作可能有些许区别。例如,在Windows的命令行当中,使用dir查看当前目录下的文件,使用del删除文件,使用copy复制文件,使用move移动文件等1。因此,在Windows当中,可以使用如del *.txt这样的命令删除当前目录下所有后缀名为.txt的文件,使用move *.jpg jpg将当前目录下所有后缀名为.jpg的文件移动到jpg目录下。
这种方式可以有效帮助你批量处理电脑中的文件。
错误处理
rm: cannot remove <路径名>: No such file or directory
在文件操作-错误处理一节当中已经介绍了这一错误,但对于通配符的使用而言,这种错误更加常见。例如,上面的例子,当你试着使用通配符*/*.dat删除1/1/data.dat文件时,由于无法匹配到对应的文件,因此则会报出这一错误。
cp: cannot stat <路径名>: No such file or directory
这一错误与上面的错误类似,都是由于文件不存在所导致的。对于使用通配符的情况,请仔细检查文件名是否正确。
3.2 grep匹配字符串
作者: Jiaqi Z.
知识点
- 如何使用
grep查找文件中的字符串
在查找与替换一节当中,已经详细介绍了如何在vi当中进行查找和替换。正如本章一开始所说的那样,很多时候我们希望在不打开vi的前提下直接找到我们所需要的信息。或者我们希望能够在一系列类似的文件中查找同样的内容1,在命令行下借助于通配符一节所介绍的内容,可以很容易实现这一点。
因此,本节我们需要了解如何在命令行当中直接查找特定字符串。同时,我们还将再一次“复习”关于正则表达式的内容(暂时只会用到初窥正则表达式一节所介绍过的内容)。
使用grep查找字符串
在Linux当中,查找文本内容的常见命令是grep,其基本语法为:grep [匹配的内容] [文件名],其中[匹配的内容]是要查找的正则表达式,而[文件名]则是希望查找的文件。
虽然说查找的是正则表达式,但实际上直接输入一个普通的字符串也是可行的。此时查找的内容就是普通的字符串查找。
同时,查找的文件可以有多个,甚至可以使用通配符。若没有提供文件名,grep将会从标准输入2中读取内容。
例如,使用grep ENCUT INCAR就可以查找在INCAR文件下所有ENCUT。
同时,还可以使用-r参数递归搜索目录下的所有文件。例如,grep -r ENCUT .表示在当前目录下递归搜索ENCUT字符串。
除此之外还有其他选项。例如,使用-v表示查找不匹配的行。例如,grep -v ENCUT INCAR表示打印INCAR文件中所有没有ENCUT的行;-i表示忽略大小写匹配;-n表示显示行号输出;-l表示只打印匹配的文件名。
其中多数选项都是可以混用的,例如,grep -l -r ENCUT .表示什么含义?
答案:递归查找当前目录下所有含有ENCUT的文件,并只输出文件名。
在grep当中使用正则表达式
在grep当中,使用正则表达式有两个地方:查找内容和文件名。关于文件名,大多数内容都如同初窥正则表达式一节和通配符一节所介绍的那样,例如,使用grep ENCUT */INCAR表示查找当前目录所有子目录下名为INCAR的文件当中含有ENCUT的行。
除此之外,在查找的内容当中,也可以使用正则表达式,此时的用法就完全类似于在vi当中使用正则表达式进行查找(见初窥正则表达式)。
错误处理
grep: <路径名>: Is a directory
这表示你尝试在目录当中查找字符串,这显然是行不通的。如果你希望查找这一路径下所有文件,可以使用grep -r <字符串> <目录名>或者grep <字符串> <目录名>/*。
sed文本替换
作者: Jiaqi Z.
知识点
- 如何使用
sed命令对文本文件进行替换 - 如何使用
sed查看文件内容 - 如何使用
sed添加(删除)文本文件的内容
在查找与替换当中,已经介绍了如何使用vim进行文本文件的替换。与vi里面的s命令类似,在命令行也有类似的方式可以对文本文件进行替换(甚至更复杂的操作)。那就是使用sed命令。
使用sed显示
sed的语法格式是:sed [选项] "<动作>" [文件路径]。其中,常见的选项包括
-n表示只有处理的文本显示在屏幕上(默认是全部文本)-i表示直接修改文件内容
在本节,我们所处理的文件都会使用-i选项直接对文件进行处理。但这一行为是危险的,尤其是对于不确定的修改操作,由于它是对原文件进行修改,因此需要提前备份。此外,千万不要将-n和-i结合起来使用,它表示仅将处理的文本修改为文件内容。
在下一节将介绍管道运算符和重定向运算符,将会帮助你避免这一问题。
如果你仔细观察上面的语法格式,需要特别注意的是里面的[文件路径]是“可选”的,也就是说,对于sed命令而言,可以不提供文件路径。这件事可能会比较“难以置信”,毕竟如果没有文件,怎样处理文件呢?
事实上,sed命令是一个管道命令,简单来说,它是可以读取并处理终端输出的内容。除此之外,像前面的grep也是类似的(虽然我们前面并没有特别强调这一点)。
在下一节,我们将详细讨论管道命令的内容。
让我们先来看一个最简单的操作——打印,即试着将特定几行的内容打印在屏幕上。其在“动作”部分的写法是<开始行号>,<结束行号>p。例如,我们希望将POSCAR的第3-5行输出,可以使用命令sed -n "3,5p" POSCAR表示输出第3-5行内容。
如果你此时忘记了-n选项的话,命令将会输出所有的POSCAR文件,但对应行号的内容会重复输出。(可以试试)
另外,如果希望对最后一行进行操作,需要使用$符号表示最后一行,但此时需要将外面的双引号变为单引号。通常情况下,双引号和单引号是等价的,但在涉及到$符号时,使用双引号则表示将$和后面的符号(例如$p)解析成变量p,而使用单引号则表明这一符号就是符号本身。变量的作用,将在后面循环和批量处理中体现,在此不做讨论。
使用sed添加和删除
使用sed命令删除某一行的方法是使用d,例如,如果希望删除POSCAR文件的第3-5行,类似于上面的显示,使用方法是sed -n "3,5d" POSCAR
这一操作是对文件内容进行删除,因此你应该谨慎使用-i选项(会直接将原文件对应内容删除),在下一节的重定向运算符将会提供灵活的解决方法。目前的一个方法是创建一个备份文件。
对于添加某行内容,可以使用a或i,前者表示新增(在下一行),后者表示插入(在上一行)。具体的,其命令为:sed [选项] "行号a(i) 添加字符串" [文件名]例如,希望在POSCAR的第一行后面添加一个字符串“1.0”,可以使用sed -n "1a 1.0" POSCAR。
那么,如果希望在第一行添加内容,应当怎么办呢?
答案:sed -n "1i 1.0" POSCAR即可。
使用sed替换
使用sed替换有两种模式,分别是整行替换和字符串替换。对于整行替换,命令为sed [选项] "行号c 替换目标字符串" [文件名]。例如,若希望将POSCAR的第2行替换为“0.8”,则可以使用命令:sed -n "2c 0.8" POSCAR。
相比于整行替换,字符串替换可能更为强大。与vim的替换类似,在sed当中替换字符串的命令是sed [选项] "s/要被替换的字符串/新字符串/g"。例如,希望在INCAR当中的ENCUT=400替换为ENCUT=600,可以使用命令sed "s/ENCUT=400/ENCUT=600/g" INCAR。
对于字符串替换而言,更重要的是支持正则表达式(关于正则表达式的内容详见初窥正则表达式一节),例如,在上面的例子中,我们希望将ENCUT=400或ENCUT=600全部替换为ENCUT=800,则可以使用sed "s/ENCUT=\d\d\d/ENCUT=800/g" INCAR
同样,由于这是对内容的删除(更改),因此需要提前备份。除非有足够的把握,否则不要使用-i选项。
错误处理
sed: -e expression #1, char 2: invalid usage of line address 0
在使用行号时,第一行是1而不是0. 通常来说,当你试图在第1行插入数据时,应当使用sed -n "1i 字符串" [文件名],其中i表示在第1行前面插入数据(即在第一行写入字符串)
管道与重定向
作者: Jiaqi Z.
知识点
- 管道运算符、如何使用管道运算符连接多个命令
- 使用重定向写入(读取)文本文件
管道
在sed文本替换一节当中,我们讨论了如何使用sed命令对文本文件进行编辑。当时我们提到,sed命令是一个管道命令,可以读取终端输出的内容。除此之外,在很多时候我们希望对某一文件进行多次操作,例如,提取某一文件的前10行,并将其中的“C”改成“B”,然后再写入新的文件当中。
像上面这种输入和输出层层传递的(一个命令的输出作为另一个命令的输入),就可以使用这一节的“管道”命令。在Linux当中,管道运算符是|(通常是Shift+Backspace下面的那个键),它的作用是把前面命令的输出作为下一个命令的参数输入。例如,我们希望将POSCAR输出,可以使用cat POSCAR,若此时又想取出前5行,则可以使用cat POSCAR | head -n 5
也许使用head -n 5 POSCAR一样可以解决上述问题,但使用管道更具有“可扩展性”。例如,cat命令本意是将多个文件连接起来,若希望将连接之后的文件读取前5行,则使用管道运算符是最简单的方法之一。
上面的过程,可以看作是将cat命令输出结果作为head命令的参数输入,之后运行head命令并输出(至标准输出),进一步,如果我们希望将其中的“C”全部替换成“B”,则需要借助于sed命令,表示为:cat POSCAR | head -n 5 | sed "s/C/B/g"
此时使用sed命令由于没有添加-i选项,因此结果也仅仅在标准输出当中进行输出,源文件并没有修改。
类似地,如果我们希望得到OUTCAR最后一个包含“without”字符串的行,在使用管道之前是“几乎不可能”的,而在利用管道时,便可以使用命令:grep without OUTCAR | tail -n 1得到结果1。
输出重定向与输入重定向
在之前,我们得到的输出结果仅仅是在屏幕上输出(也被称为“标准输出”),但必要的时候,我们也希望将结果保存至本地,以便后续处理(无论是进一步使用程序语言读取并处理,还是过一段时间再看)。正因如此,寻找一种方法将输出结果保存就十分重要。
在Linux当中,保存终端输出的本质就是“将输出重定向至文件”,其运算符是>或>>,后面需要有一个文件名路径表示希望写入的文件。其中,前者(>)表示创建,当文件存在时则会覆盖;后者(>>)表示追加,当文件不存在时新建,存在时则会在后面追加新的内容。
有了这一方法,我们终于可以解决sed文本替换一节所遗留的关键问题:如何将编辑后的文件保存至新的文件?答案就是使用重定向运算符。例如,我们希望将INCAR文件里面的ENCUT=400改为ENCUT=600并保存至INCAR2,则可以使用命令:sed "s/ENCUT=400/ENCUT=600/g" INCAR > INCAR2
再一个例子,如果希望将Si/POTCAR和O/POTCAR合并至一个新的POTCAR当中,应当怎样写呢?
cat Si/POTCAR O/POTCAR > POTCAR
请注意运算符是>而不是<,前者表示“输出重定向”,而后者表示“输入重定向”,即将文件的内容作为命令的输入。例如,cat < POSCAR与cat POSCAR等价。
二者的方向虽然容易混淆,但似乎可以从箭头的方向看出一点规律——>表示将命令的内容“输出至”文件中,而<表示将文件“输入至”命令中。
在必要的时候,我们当然也可以将输入和输出同时重定向,例如,cat < POSCAR > POSCAR2也是可行的(将POSCAR重定向输入至cat命令,并将命令输出结果重定向至POSCAR2输出)
除了“标准输入”和“标准输出”之外,Linux还有一个“标准错误输出”,用来输出命令运行报错的结果。例如,当我们希望删除一个名为POSCUT的文件时(该文件并不存在),使用rm POSCUT会报错(这一点在文件操作已经详细讨论过了)。如果试图将这一输出重定向,例如,rm POSCUT > output,效果是一样的。但如果使用rm POSCUT 2> output呢?你会发现,终端没有报错了,而将报错输出至文件outcar当中了。这其中,2>就表示将“标准错误输出”重定向至后面的文件。
在这一基础上,稍微扩展一下。在后面的VASP教程中,我们将看到提交脚本中有mpirun vasp_std > vasp.out 2>vasp.err这一行2。暂且忽略掉前面的mpirun(表示分布式计算系统下并行运行任务),可以发现,这一行的作用就是运行vasp_std,并将输出结果输出至vasp.out,而将错误信息输出至vasp.err。
另外,我们这里重定向的文件并不一定是文本文件。如果你回顾一下查看文件-Linux文件类型一节,可能会发现里面有一个“设备文件”,它也是可以作为重定向输入输出的一部分。例如,rm POSCUT 2> /dev/null则表示将输出报错信息重定向至/dev/null设备(这是一个“空设备”,用于消除所输出的内容)。运行这一命令,你将不会得到任何输出结果(输出被消除了)
错误处理
使用cat << POSCAR没有反应
如果你确实希望使用输入重定向,应当注意是<(一个)而不是<<(两个)。后者在Linux中通常用于终端交互中,例如,上面的命令表示将POSCAR之间的内容作为输入。一个演示例子为:
$ cat << POSCAR
> hello
> world
> POSCAR
hello
world
可以看到,它把“POSCAR”之间的内容传入了cat命令(输出)
什么是声子、声子谱
作者:Isay K.
知识点
- 声子
- 声子谱
声子
声子(Phonon),即“晶格振动的简正模能量量子”,是晶体中原子振动的量子化描述。
在固体物理学中,声子是晶格振动的准粒子,其携带能量和动量,并且可以像粒子一样进行相互作用。
声子是简谐近似下的产物,如果振动太剧烈,超过小振动的范围,那么晶格振动就要用非简谐振动理论描述。
声子并不是一个真正的粒子,声子可以产生和湮灭,有相互作用的声子数不守恒,声子动量的守恒律也不同于一般的粒子,并且声子不能脱离固体存在。声子只是格波激发的量子,在多体理论中称为集体振荡的元激发或准粒子。
声子的化学势为零,属于玻色子,服从玻色-爱因斯坦统计。声子本身并不具有物理动量,但是携带有准动量,并具有能量,它的能量等于。
声子可以分为以下两类:
- 声学支:与晶格的纵向和横向振动相关,类似于声波,表示原胞的整体振动。
- 光学支:与晶格的非均匀振动相关,通常与电荷的重新分布有关,表示原胞内原子间的相互振动。
如果一个材料的原胞中有个原子,那么声子谱就会有支,其中3条声学支,条光学支。
声子谱
声子谱,也称为声子色散关系,是描述声子能量与动量之间关系的图表。
声子谱通常在第一布里渊区内绘制,因为其包含了所有可能的声子模式。
通常,使用声子谱研究体系的动力学稳定性,使用分子动力学研究体系的热力学稳定性。
声子谱的其他物理意义:
- 电子-声子耦合:在半导体和超导体中,电子-声子耦合相互作用对材料的电子性质至关重要;
- 声子散射:在金属和半导体中,声子散射是影响电子迁移率的关键因素;
- 热容:声子谱可以解释材料在不同温度下的热容行为
- ...
计算方法简介
作者:Isay K.
知识点
- 密度泛函微扰理论(DFPT)
- 有限位移法(Finite Displacement Method)
- 适用情境比较
密度泛函微扰理论(DFPT)
DFPT是一种基于第一性原理的方法,它直接从周期性边界条件的Kohn-Sham波函数计算出声子谱。在DFPT中,通过计算原子间相互作用的微扰来得到力常数矩阵,这是描述晶格动力学性质的关键量。
有限位移法(Finite Displacement Method)
有限位移法通过在超原胞中引入原子的有限位移来模拟晶格振动。这种方法基于位移-响应理论,通过计算原子位移后系统的受力来构造动力学矩阵
适用情境比较
DFPT适用情境:
- 需要高精度声子谱的系统,尤其是小到中等大小的晶胞;
- 研究者希望避免有限位移法可能引入的系统误差时。
有限声子法适用情境:
- 当计算资源有限或需要对多种材料进行筛选时;
- 对于大晶胞材料的初步声子谱分析。
总得来说,对于较重的任务,DFPT方法可能会造成内存溢出,且DFPT方法由于其特性而无法进行并行计算,而有限声子法可以并行。对于较小的体系,可以根据需要和组内资源选择方法。
建议优先使用有限位移法。
一些教程中有时候将有限位移法又称为冷冻声子法或直接法。 但笔者并没有找到更官方的资料说明有限位移法和冷冻声子法是同一种方法,谨奉上PHONOPY官网供读者自行分辨。
计算软件PHONOPY
作者:Isay K.
知识点
- 开始安装之前
- PHONOPY快速安装
- PHONOPY使用方法
开始安装之前
由于本教程面向的群体是计算小白(包括笔者也是通过本教程记录一下自己掉的坑),所以在开始安装软件之前,我们强烈建议先咨询组内老师或师兄师姐:服务器上是否已经配置了相应的软件?
通常情况下,组内服务器的根目录下已经配置了相应的软件,这个时候再在自己的用户目录下进行配置的话,一方面在使用过程中可能会出现命令的冲突,另一方面也是一种时间、精力和资源的浪费。
如果组内确实并没有安装,或者你是传说中的开山大弟子,又或者是自学,请放心进入PHONOPY快速安装小节。PHONOPY快速安装
参考:https://blog.csdn.net/qq_41866202/article/details/124407208?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ECtr-1-124407208-blog-139391379.235%5Ev43%5Epc_blog_bottom_relevance_base9&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ECtr-1-124407208-blog-139391379.235%5Ev43%5Epc_blog_bottom_relevance_base9&utm_relevant_index=1PHONOPY使用方法
加载PHONOPY环境
- 加载Anaconda应用:
module load conda - 激活PHONOPY环境:
conda activate PHONOPY
命令详解
进入下面的官网之后点击Command options即可看到所有功能。
https://phonopy.github.io/phonopy/index.html在进行扩胞时的标准是:扩胞后的原子达到80~100个,每个晶轴方向大于10,不然得到的声子谱中很容易出现虚频。
具体计算步骤
作者:Isay K.
知识点
- 计算声子谱前的结构优化
- DFPT方法计算声子谱
- 有限位移法计算声子谱
计算声子谱前的结构优化
在计算声子时需要先对原胞结构做高精度的结构优化,不然得到的声子谱中很容易出现虚频。
我们以TiTe2为例,以下是高精度优化的具体参数。
INCAR
Global Parameters
ISTART = 1
ISPIN = 1
LREAL = .FALSE.
ENCUT = 380
LWAVE = .FALSE.
LCHARG = .FALSE.
ADDGRID= .TRUE.
LASPH = .TRUE.
PREC = Accurate
NCORE = 8
ISYM = 0
Lattice Relaxation
NSW = 300
ISMEAR = 0
SIGMA = 0.03
IBRION = 2
ISIF = 3
IOPTCELL = 1 0 0 1 1 0 0 0 0
EDIFF = 1E-08
EDIFFG = -1E-03
为了保证优化精度足够高,其中需要注意的是:
EDIFF表示电子收敛标准,至少要取1E-06,体系小的话尽量取1E-08;EDIFFG取负值时表示力收敛标准,取\1E-03;ADDGRID表示是否添加额外网格提高精度,设定为.TRUE.;PREC表示“精度”模式,设定为Accurate(准确);NSW表示电子优化步数,取300防止计算中断;ENCUT可以自行做测试,详见VASP计算-结构优化章节(先别去找,我没写);
另外,其中ISIF=3表示既优化晶格又优化原子坐标,配合IOPTCELL可以实现晶轴的单独固定,以达到计算二维材料的目的,详见VASP计算-结构优化章节(也还没写)。
下面的其他输入文件没有需要特别说明的,如有疑问请参考VASP计算-结构优化章节(哈哈,又是这)或参考VASP官网:https://www.vasp.at/wiki/index.php/The_VASP_Manual
KPOINTS
A
0
Gamma
24 24 1
0.0 0.0 0.0
POSCAR
TiTe2-1m1
1.00000000000000
3.7458432095936396 -0.0000184453725456 0.0000000000000000
-1.8729216047968198 3.2439861579338527 0.0000000000000000
0.0000000000000000 0.0000000000000000 18.0000000000000000
Ti Te
1 2
Direct
0.0000000000000000 0.0000000000000000 0.5127400160000022
0.6666666132020026 0.3333334158033583 0.6098496477195335
0.3333334157979960 0.6666666131966403 0.4156403382804701
0.00000000E+00 0.00000000E+00 0.00000000E+00
0.00000000E+00 0.00000000E+00 0.00000000E+00
0.00000000E+00 0.00000000E+00 0.00000000E+00
提交任务进行计算,得到?CONTCAR为优化后的更合理的结构,作为后续声子计算的初始晶胞。
(后续小节中提到“初始晶胞”均指优化后得到的晶胞,为避免歧义在此说明。)
DFPT方法计算声子谱
1.mkdir method_DFPT
新建文件夹。
2.cp relax/CONTCAR method_DFPT/POSCAR
将上一步高精度结构优化得到的CONTCAR复制进文件夹内,并重命名为POSCAR。
3.cd method_DFPT
进入新文件夹。
4.module load conda
conda activate phonopy
加载conda模块,并激活phonopy环境,详情可参考PHONOPY使用方法
5.phonopy -d --dim="6 6 1"
使用PHONOPY进行6×6的扩胞。
此时会产生数个名为POSCAR-0?的位移文件,以及名为SPOSCAR的扩胞后的结构。
DFPT方法使用的是SPOSCAR,而有限位移法使用的是这些位移文件。
笔者研究的是2D结构,仅对两个方向进行扩胞,读者可根据需要自行调整。 扩胞的标准是扩胞后达到80~100个原子,且晶轴长度大于10埃,不然得到的声子谱中很容易出现虚频。
此外,如果所考虑的体系为掺杂体系,由于本身体系就已经扩胞(由于掺杂),在计算声子谱时,往往不需要再进行扩胞。在这里只使用phonopy -d --dim="1 1 1"即可。
6.mkdir vasp-calculations
新建文件夹用于后续计算。
此处根据个人习惯不同,也可以不新建文件夹。将POSCAR重命名为POSCAR-unit,将第5步新产生的SPOSCAR重命名为POSCAR,直接在当前文件夹中进行计算。
7.cp SPOSCAR vasp-calculations/POSCAR
将第5步新产生的SPOSCAR复制进文件夹,并重命名为POSCAR。
8.准备其它基本文件:
INCAR
SYSTEM = TiTe2
#ISIF = 3
NSW = 1
IBRION = 8
LWAVE = F
LCHARG = F
ENCUT = 380
EDIFF = 1E-8
EDIFFG =-1E-3
ISMEAR = 0
LREAL = F
SIGMA = 0.03
PREC = A
ADDGRID = .TRUE.
KPOINTS
A
0
Gamma
3 3 1
0.0 0.0 0.0
9.sbatch sub.vasp
提交任务进行计算。
10.cd ..
返回method_DFPT文件夹。
11.cp vasp-calculations/vasprun.xml .
将vasprun.xml复制到当前文件夹。
12.phonopy --fc vasprun.xml
使用phonopy读取vasprun.xml生成力常数文件FORCE_CONSTANTS。
13.vi band.conf
编辑band.conf文件:
band.conf
ATOM_NAME =Ti Te
DIM = 6 6 1
BAND =0 0 0 0.5 0 0 0.33333 0.33333 0 0 0 0
BAND_POINTS = 101
FORCE_CONSTANTS = READ
-
DIM根据体系的扩胞大小设置,如扩胞扩到332,就设置成332。 BAND和能带的取点是一样的,也可以用vaspkit生成。FORCE_CONSTANTS一定设置成READ。- 更多设置可以看PHONOPY官网。
14.phonopy -p -s band.conf
使用phonopy读取band.conf文件,作图并保存。
15.phonopy-bandplot --gnuplot > phonon.out
将数据导出方便后续用Origin等软件重新绘图。
旧版本的phonopy的导出命令为:bandplot --gnuplot> phonon.out
有限位移法计算声子谱
1.mkdir method_yxwy
2.cp relax/CONTCAR method_yxwy/POSCAR
3.cd method_yxwy
4.phonopy -d --dim="6 6 1"
前四步和DFPT法完全相同。
5.for i in {01..12}; do mkdir $i; cp POSCAR-0$i $i/POSCAR;done
假如第四步产生了12个位移文件,使用for循环生成12个文件夹,并将对应的位移POSCAR移入文件夹重命名为POSCAR。
6.准备其它基本文件:
INCAR
ADDGRID = .TRUE.
PREC = Accurate
IBRION = -1
ENCUT = 380
EDIFF = 1E-8
EDIFFG = -1E-3
ISMEAR = 0
SIGMA = 0.03
IALGO = 38
LREAL = .FALSE.
LWAVE = .FALSE.
LCHARG = .FALSE.
NCORE = 4
有限位移法的单个计算实际上就是高精度的静态自洽。
KPOINTS
Automatic mesh
0
Gamma
3 3 1
0 0 0
同DFPT法一样,有限位移法使用的也是扩胞之后的结构,所以K点没有必要取太大。
7.for i in {01..12}; do cp INCAR KPOINTS POTCAR sub.vasp $i; cd $i; sbatch sub.vasp; cd $OLDPWD;done
将基本文件复制进各个小文件夹中并进行计算。
8.phonopy -f {01..12}/vasprun.xml
计算全部结束后,使用phonopy读取全部的计算文件夹中的vasprun.xml,生成FORCE_SETS文件。
9.vi band.conf
band.conf
ATOM_NAME =Ti Te
DIM = 6 6 1
BAND =0 0 0 0.5 0 0 0.33333 0.33333 0 0 0 0
BAND_POINTS = 101
FORCE_SETS = READ
与DFPT方法唯一不同的部分在于将FORCE_CONSTANTS=READ改成FORCE_SETS=READ。
10.phonopy -p -s band.conf
使用phonopy读取band.conf文件,作图并保存。
11.phonopy-bandplot --gnuplot > phonon.out
将数据导出方便后续用Origin等软件重新绘图。
错误处理
作者:Isay K.
vasprun.xml没有必要信息
能带理论基础
作者:Jiaqi Z.
知识点
- 什么是能带
- 能带的三个重要近似
在本章,我们将要了解材料计算的一个重要内容--关于能带的计算。毫不夸张地说,能带论是目前研究固体中的电子状态,说明固体性质最重要的理论基础。一个最简单的例子是,利用能带的相关计算,我们可以从严格的角度判断材料的导电性。
导体和绝缘体的概念,贯穿了我们的学习生涯。而这一概念也在随着认知水平的增长发生变化。
最开始接触的时候,我们认为,导体是那些带有电荷的物质,而绝缘体内部没有电荷。这一结论是我们对“电”和“电荷”的初步认识,显然是不准确的。进一步学习了物理后,我们了解到:任何原子都是由原子核和电子组成的,所谓的导体,就是存在“自由移动的电子”,相反,绝缘体就是没有自由电子的物质。这一概念结合了原子和电子的认识,相比于最开始的“电荷”,显然更准确了。
到了现在,我们将要了解到能带。基于能带理论,在导体中,价带(价电子所在的能带)和导带(电子可以自由移动的能带)是重叠的,或者价带顶部和导带底部之间的能隙(带隙)非常小,甚至为零。这意味着电子可以轻易地从价带跃迁到导带,从而在电场作用下自由移动,形成电流。而对于半导体而言,价带和导带之间存在一个较大的带隙,电子要跃迁到导带需要吸收足够的能量(如热能或光能)。在常温下,电子通常没有足够的能量来跃迁,因此电子不能自由移动,导致绝缘体不导电。
什么是能带
从原子物理的知识来看,一个孤立原子的电子只能处在特定的能级当中。而我们所计算的材料,往往是周期性的多原子材料1。对于多原子而言,电子和电子之间、电子和原子核之间会产生相互作用,此时电子的能级就会发生“展宽”,从而变成一系列的带状结构。称为“能带”。
通常情况下,能带仅在周期性材料中讨论。对于单分子(如气体分子等),计算能带往往没有意义。
能带理论的三个近似
我们不会在这一教程中详细介绍能带的推导过程,但是我们还是有必要在这里提到三个重要的近似。这些近似可以说是能带理论的基础,甚至可以说是整个第一性原理计算的基础。
- Born-Oppenheimer近似,又名绝热近似:因为原子核比电子重的多,所以原子核比电子具有更大的惯性,更难运动。因此,我们只考虑电子的运动,原子核是被固定住的。
- 单电子近似(独立电子近似、平均场近似):将电子与电子相互作用等效成一个平均值,电子是在一个平均场中运动。
- 周期场近似:平均场是周期性的。
具体内容在任何一本固体物理教材中都会详细提到,这里不再赘述。
VASP计算能带过程
作者:Jiaqi Z.
知识点
- 如何使用VASP计算PBE能带
在本节,我们将详细讨论如何使用VASP计算能带。我们先讨论最简单的PBE能带计算过程,旨在通过这一流程,掌握计算能带的完整步骤。在这一基础上,后面将会详细讨论精度更高的计算方法(如HSE能带计算等)。
使用PBE计算能带往往会得到较小的带隙,如果你使用数据库或文献中的能带图进行复现,可能会得到与文献不同的带隙。这一点是PBE泛函计算能带所固有的缺陷。
结构优化
在这一部分计算能带时我们使用SiO2为例进行分析。所使用数据库来源自Materials Project。
SiO2的结构文件POSCAR如下所示:
Si2 O4
1.0
5.1358423233 0.0000000000 0.0000000000
0.1578526541 5.1334159104 0.0000000000
-2.6468476750 -2.5667081359 3.5753437737
Si O
2 4
Direct
0.750000000 0.250000000 0.500000000
0.000000000 0.000000000 0.000000000
0.787033975 0.625000000 0.662033975
0.875000000 0.212965995 0.837966025
0.962966025 0.125000000 0.337965995
0.375000000 0.037034001 0.162034005
vaspkit-602,可以得到PRIMCELL.vasp文件,将其重命名为POSCAR文件即可。
对于一些特殊情形(例如需要掺杂等情况),不得不使用超胞进行计算。如果确实需要计算能带结构,往往需要对能带进行反折叠以得到更清楚的图像。我们将在后面的部分对这一技术进行讨论。
目前,我们所讨论的结构都是原胞。
在计算能带之前,首先需要对材料进行结构优化。为得到结构优化所用INCAR文件,使用vaspkit-101-LR生成。同时调整其中的部分参数,修改后的INCAR文件如下:
Global Parameters
ISTART = 1
LREAL = .FALSE.
ENCUT = 600
PREC = Accurate
LWAVE = .TRUE.
LCHARG = .TRUE.
ADDGRID= .TRUE.
Lattice Relaxation
NSW = 300
ISMEAR = 0
SIGMA = 0.05
IBRION = 2
ISIF = 3
EDIFFG = -1.5E-02
其中,需要特别注意并调整的是:
ENCUT:截断能。通常设置为600或更高,但更高的截断能往往意味着更长的机时。同时,在后续所有计算中,截断能应当保持不变。ISIF:表示优化方式。对于一般的结构优化,通常设置为ISIF=3表示优化原子坐标和晶格参数。对于一些特殊的材料(如二维材料),一些晶格参数可能不希望发生变化,此时可以设置OPTCELL文件,其内容为$3\times3$的矩阵,分别对应POSCAR当中的晶格参数坐标。其元素可以是0(表示不优化该坐标)或1(表示优化该坐标)。对于晶格参数不变的情况,可以设置为ISIF=2表示只优化原子坐标。EDIFFG:表示优化收敛标准。其中正数表示能量收敛标准(即能量变化小于这一数值时停止计算),而负数表示力收敛标准(原子作用力小于这一数值的绝对值时停止计算)。NSW:表示最大离子步。当优化离子步达到设定数值时停止计算(此时往往未达到收敛标准,需要重新计算)。或者,当EDIFFG=0时,计算达到设定NSW时停止计算。
对于KPOINTS文件,在结构优化时可以使用“自洽计算”的K点,使用vaspkit-102生成,通常设定Gamma点(2),选择密度时通常设定为0.02-0.04即可。
本例使用vaspkit-102-2-0.02生成KPOINTS文件如下所示:
K-Spacing Value to Generate K-Mesh: 0.020
0
Gamma
12 12 14
0.0 0.0 0.0
POTCAR。但为了确保生成文件的正确性,建议使用grep TITEL POTCAR查看赝势文件是否正确(与POSCAR文件相比较)1。
将以上文件放置在一个目录下,提交任务计算后得到CONTCAR文件,即为优化后得到的结构文件。
自洽计算
计算完成后,新建一个目录(例如命名为scf),将结构优化得到的CONTCAR文件复制(或移动)到scf目录内,并重命名为POSCAR。
将结构优化的KPOINTS和POTCAR复制(或移动)到scf目录内。
使用vaspkit-101-ST命令生成自洽计算所需要的INCAR文件。其中需要将截断能ENCUT设置为结构优化所使用的标准。修改后得到的INCAR文件如下所示:
Global Parameters
ISTART = 1
LREAL = .FALSE.
ENCUT = 600
PREC = Accurate
LWAVE = .FALSE.
LCHARG = .TRUE.
ADDGRID= .TRUE.
Static Calculation
ISMEAR = 0
SIGMA = 0.05
LORBIT = 11
NEDOS = 2001
NELM = 60
EDIFF = 1E-08
其中需要特别注意的设置是:
LWAVE:表示写入波函数文件WAVECAR,通常用于继续计算时的初始化设定。由于文件较大,因此如无必要,通常可以将其设定为.FALSE.表示不写入文件。LCHARG:表示写入电荷密度文件CHGCAR。在计算能带时,由于需要使用到这一文件,因此需要将其设定为.TRUE.。EDIFF:表示电子收敛标准。当能量变化达到这一标准时结束迭代计算。
将所有文件准备好后提交任务。
能带计算
相比于自洽计算,能带计算所需要的K点是特殊的高对称点路径,因此关键在于KPOINTS的生成。
将自洽计算得到的CHGCAR, POSCAR, INCAR, POTCAR全部复制(或移动)到一个新的目录下(假设为band)。
vaspkit-3生成计算能带所用KPOINTS文件。其中需要根据结构特点选择是二维材料还是三维材料,在本例中由于SiO2是三维材料,因此使用KPOINTS-303生成KPATH.in文件,将其命名为KPOINTS文件。生成后得到的文件如下所示。
K-Path Generated by VASPKIT.
20
Line-Mode
Reciprocal
0.0000000000 0.0000000000 0.0000000000 GAMMA
0.0000000000 0.0000000000 0.5000000000 X
0.0000000000 0.0000000000 0.5000000000 X
0.2500000000 0.2500000000 0.2500000000 P
0.2500000000 0.2500000000 0.2500000000 P
0.0000000000 0.5000000000 0.0000000000 N
0.0000000000 0.5000000000 0.0000000000 N
0.0000000000 0.0000000000 0.0000000000 GAMMA
0.0000000000 0.0000000000 0.0000000000 GAMMA
0.5000000000 0.5000000000 -0.5000000000 M
0.5000000000 0.5000000000 -0.5000000000 M
0.3674577537 0.6325422463 -0.3674577537 S
-0.3674577537 0.3674577537 0.3674577537 S_0
0.0000000000 0.0000000000 0.0000000000 GAMMA
0.0000000000 0.0000000000 0.5000000000 X
-0.2349155075 0.2349155075 0.5000000000 R
0.5000000000 0.5000000000 -0.2349155075 G
0.5000000000 0.5000000000 -0.5000000000 M
其中每相邻两个点都是对应于一条高对称点路径。
对于INCAR文件,需要在自洽所使用文件的基础上,添加ICHARG=11表示读取当前目录下的CHGCAR文件,从而用于非自洽计算。
将以上文件整理后提交任务计算。至此我们就已经完成了VASP计算能带的所有过程。
能带绘图与后处理
作者:Jiaqi Z.
知识点
- 如何使用Origin绘制能带图
- 如何使用vaspkit自动生成能带图
在上一节的计算中,我们已经得到了能带所需要的全部信息。但是,使用计算软件得到的仅仅是数据,与我们所需要的“能带图”还差一个步骤--数据后处理。
在这一节,我们将讨论如何借助于vaspkit软件绘制能带图。其中,最基本的方法是使用Origin绘图,但在vaspkit的更新过程中,也添加了借助于Python脚本自动绘图的功能。我们将在本节首先介绍如何配置可自动绘图的vaspkit,然后介绍如何使用vaspkit自动绘图。
使用Origin绘制能带图
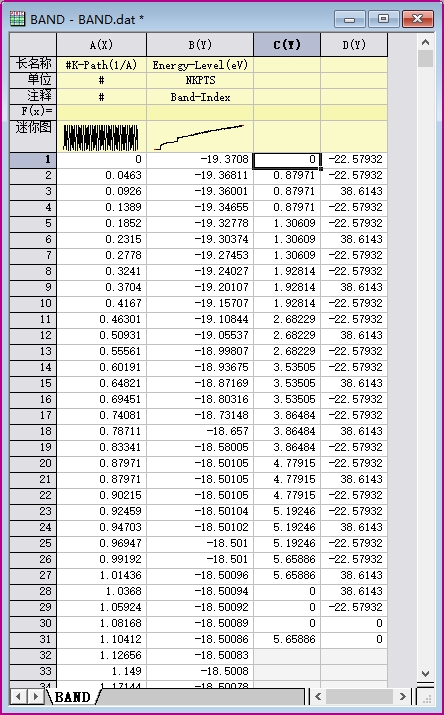
使用Origin绘制能带图的第一步是得到能带图上每一点的坐标,借助于vaspkit我们可以很容易实现。利用vaspkit-211可以得到绘制能带图所需要的BAND.dat文件,其中包含了能带图的数据点坐标,下面则是文件开始的一部分:
#K-Path(1/A) Energy-Level(eV)
# NKPTS & NBANDS: 180 64
# Band-Index 1
0.00000 -19.370800
0.04630 -19.368108
0.09260 -19.360010
0.13890 -19.346551
0.18520 -19.327775
0.23150 -19.303736
0.27780 -19.274533
除此之外,我们还会得到KLINES.dat文件,用于生成高对称点坐BAND.dat文件后新添一列,并将KLINES.dat文件复制到新添的列中,得到的文件如图所示。
将新添加的C列(KLINES.dat文件中的x坐标的属性设置为“X”(方法:右键点击上方列名-“设置为”-X)
将这4列数据全选后点击菜单栏“绘图”-“基础2D图”-“折线图”即可得到所绘制的能带如图所示。
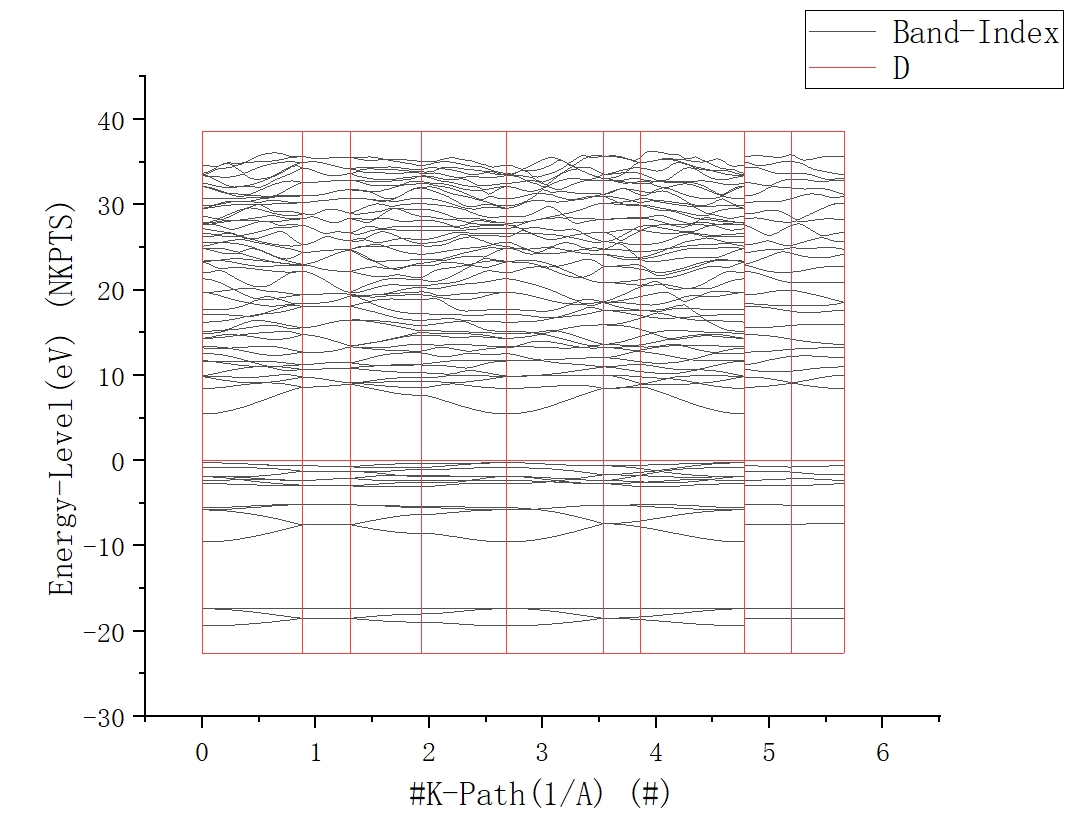
调整线型与坐标范围,并在下方添加高对称点标签(可以借助于vaspkit生成的KLABELS文件,其中包含所有高对称点坐标所对应的x轴坐标)
一般来说,默认生成的能带图都会如上图所示包含较多的能带。但在实际研究中,我们往往仅关心费米能级附近(即0点附近)的情况。此时除了可以使用Origin调整坐标轴范围的方法,也可以在使用VASP计算自洽和能带的时候使用NBANDS参数,设置需要显示的能带数量。
在使用vaspkit自动生成能带图时,则需要对这一参数进行设置。
处理后得到的能带图如图所示1
使用vaspkit自动生成能带图
自1.2.5版本之后,vaspkit更新了自动绘图的功能。利用这一功能,可以不将数据下载至本地后使用Origin绘图,而是直接在Linux操作系统中得到能带图像。
使用vaspkit自动绘图的过程是比较简单的,但我们需要提前对vaspkit做一些配置上的设置。
vaspkit配置过程
请首先检查你所使用的vaspkit是否为1.2.5或更新版本。你可以直接使用vaspkit命令,在菜单栏上方,可以查看所使用的软件版本。
同时,你还应当确认你的系统上已经配置了Python相关环境,以及绘图所必须的matplotlib包。通常,使用Anaconda可以“一次性”完成Python所需要的所有配置。确认是否安装Anaconda的一个方法是使用命令conda --version,若输出版本号,则表明已经配置了Anaconda2。
如果存在没有的命令或模块,可能需要重新安装。详细安装过程请查阅对应软件官网3,4的说明。
假设你的系统已经确认可以配置,在开始之前还需要做如下操作:
- 使用
which python3查看python3所在目录。你需要记住这一路径,将其首先复制到本地的记事本或其他地方是一个好方法; - 使用
which vaspkit查看vaspkit所在目录,并使用cd命令进入这一目录(通常只需要进入到版本号所在目录即可,例如,在我所在课题组当中,目录为/opt/pub/softwares/VASPKIT/1.5.1); - 在这一目录下,找到
how_to_set_environment_variables文件,并将其中从#BEGIN_CUSTOMIZE_PLOT到#END_CUSTOMIZE_PLOT之间的所有内容(包括这两行)复制到某个地方,以便稍后使用; - 回到所在家目录,新建一个
.vaspkit文件,并在其中创建如下两行:
其中,PYTHON_BIN /opt/pub/toolkits/anaconda3/bin/python3 AUTO_PLOT .TRUE.PYTHON_BIN后面对应的是之前所复制的python3所在目录。然后,在文件下方将所复制的#BEGIN_CUSTOMIZE_PLOT到#END_CUSTOMIZE_PLOT之间的所有内容粘贴至后面。
使用vaspkit绘图
在使用vaspkit绘图前,应当首先保证你已经导入了相应模块(如Anaconda等)。与正常使用vaspkit导出能带图类似,在使用vaspkit-211导出时,会询问导出图片是仅导出能带图,还是能带图加态密度。我们在这里选择仅绘制能带图(1),得到如图所示的图像。
EMIN和EMAX参数设置能量区间。
如何计算带隙
有时,我们可能不是强制要求需要得到能带图,而仅仅关注结构的带隙性质(如带隙大小,类型等)。此时,可以直接使用在绘图过程中生成的BAND_GAP文件(使用vaspkit-211生成)。以SiO2为例,文件内容为:
Band Character: Direct
Band Gap (eV): 5.7105
Eigenvalue of VBM (eV): -0.6699
Eigenvalue of CBM (eV): 5.0407
Fermi Energy (eV): -0.4270
HOMO & LUMO Bands: 16 17
Location of VBM: -0.000000 0.000000 0.000000
Location of CBM: -0.000000 0.000000 0.000000
其中,Band Character表明带隙类型是直接带隙(Direct)或间接带隙(Inderect);Band Gap表明所计算结构的带隙大小,在本例中为5.71 eV。除此之外,这一文件还提供了如HOMO(最高占据分子轨道)和LUMO(最低未占据分子轨道)所对应的能带条数,以及VBM(价带顶)和CBM(导带底)所对应的K点坐标。
如果你关注过最开始Materials Project所记录的数据,可能会发现,数据库内所给的带隙约为5.8 eV。而我们所计算得到的比实际带隙小了约0.1 eV。正如“VASP计算能带过程”一节开始所说的那样,这一误差是由于PBE泛函所导致的,而这是PBE泛函的固有缺陷。在一些需要精确计算的情况下,我们可能希望计算HSE能带而不是PBE能带。
HSE能带计算
作者: Jiaqi Z.
知识点
- 如何计算HSE能带
在之前介绍PBE能带计算时提到,使用PBE计算会得到带隙偏小的情况,而这对于高精度计算显然是不合适的。因此,在大多数计算能带的论文中都需要其他泛函如HSE计算得到的能带。因此,在本节我们将讨论如何使用HSE计算能带并给出更加准确的带隙。
结构优化与自洽计算
在本节我们将讨论的结构是金刚石,其POSCAR文件如下所示:
C2
1.0
2.5269944668 0.0000000000 0.0000000000
1.2634972334 2.1884414035 0.0000000000
1.2634972334 0.7294804678 2.0632823422
C
2
Direct
0.750000000 0.750000000 0.750000000
0.500000000 0.500000000 0.500000000
对于HSE泛函计算能带,结构优化过程与前面VASP计算能带过程-结构优化所介绍的步骤完全相同,因此这里不再赘述。
对于自洽计算,KPOINTS则需要使用hse的K点。生成方法可以使用vaspkit-3-302/303生成KPATH.in后使用vaspkit-25-251生成KPOINTS,其中可以根据需要选择Monkhorst-Pack Scheme或Gamma Scheme方法生成K点1。然后需要依次输入scf所使用k点密度(通常设定为0.04)以及计算能带所需要的k点密度(通常也设定为0.04)
同时,在计算scf时还需要将INCAR的LWAVE = .TRUE.以生成波函数文件,以便计算能带时使用。下面是一个参考使用的INCAR文件:
Global Parameters
ISTART = 1
ISPIN = 1
LREAL = .FALSE.
ENCUT = 600
PREC = Accurate
LWAVE = .TRUE.
LCHARG = .FALSE.
ADDGRID= .TRUE.
Static Calculation
ISMEAR = 0
SIGMA = 0.05
LORBIT = 11
NEDOS = 2001
NELM = 60
EDIFF = 1E-08
HSE能带计算
上一步计算完成后,将KPOINTS, POTCAR, POSCAR和WAVECAR文件拷贝(或移动)至新的目录(暂且命名为hse-band,使用vaspkit-101-STH6生成HSE计算的INCAR文件,调整必要的参数后如下所示:
Global Parameters
ISTART = 1
ISPIN = 1
LREAL = .FALSE.
ENCUT = 600
PREC = Accurate
LWAVE = .FALSE.
LCHARG = .FALSE.
ADDGRID= .TRUE.
Static Calculation
ISMEAR = 0
SIGMA = 0.05
LORBIT = 11
NEDOS = 2001
NELM = 60
EDIFF = 1E-08
HSE06 Calculation
LHFCALC= .TRUE.
AEXX = 0.25
HFSCREEN= 0.2
ALGO = ALL
TIME = 0.4
PRECFOCK= N
这里面的关键参数是AEXX,表示杂化泛函所占的比重,通常设定为0.25是比较合适的。但这一比值会影响到带隙的大小,因此在必要的时候需要进行调整以适应实验结果。
将上述文件提交计算,由于HSE能带计算精度较高,因此需要时间较长2。
HSE能带计算后处理
与能带绘图与后处理一节所介绍的类似,在HSE计算后也需要对数据进行处理,绘图。但在一些细节上有些许不同:
- 在绘制能带图之前,需要确保当前目录下有
KPATH.in文件(可以直接使用vaspkit-3-302/303的方式生成,也可以直接从之前scf目录下复制过来; - 使用
vaspkit-25-252生成能带数据,所得到的BAND.dat和KLINE.dat文件可以将其放入Origin等软件中绘图(方法参考能带绘图与后处理一节,在此略)
生成能带数据后,可以通过BAND_GAP文件查看计算得到的带隙。在本地测试时,得到结果为5.29 eV,与文献3结果5.38 eV接近。
同时,我们也可以利用VASP计算能带过程所介绍的PBE能带计算方法,对金刚石的PBE带隙进行计算。结果发现其带隙为4.12 eV,显然小于HSE带隙。
简单for循环
作者: Jiaqi Z.
知识点
- 命令行
for循环的基本结构 - 如何使用
for循环批量处理任务 $OLDPWD变量的使用
在这一章的最后,让我们看一下关于命令行的最后一个话题——批量处理。其中,批量处理的一个基本方法是使用for循环语句。
更复杂的批量处理可能需要配合下一章介绍的bash批处理脚本,那里面会有进一步复杂的如条件判断等。一般来说,更复杂的批量处理会放到脚本中执行。在本节,我们仅仅讨论一些能使用for循环简单处理的任务。
虽然说是“最后一个话题”,但实际上关于命令行的使用远不止此。只不过目前教程(或者说科研过程中)可能涉猎到的也就这些。一些更复杂的,或者更细节的使用,例如系统本身操作等,我们并没有对此进行讲解。对于需要的人来说(例如服务器维护相关人员),请查阅更专业的书籍或相关手册了解更多如系统目录架构,以及服务器维护,root权限等相关内容。1
对于一些后续可能会用到的命令,会有新的补充,请继续关注仓库内版本更新,或者网页端动态更新。
for语句基本结构
在Linux当中,for语句的基本结构为:for [变量名] in [列表范围]; do [要执行的语句]; done。其中,[列表范围]可以使用大括号将其依次列出,例如{a,b,c,d,e}表示遍历这五个字母。同时,在do后面需要是按顺序执行的语句,其中每一个语句后面以分号(;)结尾。
在Linux当中,分号表示一个命令的结束,对于最后一个语句可以不加分号(此时回车表示结束)。例如,希望一次性输出POSCAR和CONTCAR文件的最后几行,可以一次性运行两句命令tail POSCAR; tail CONTCAR,其中分号表示这是两个语句。
在for循环中,你也可以这样理解分号,其中done前面只需要有一个分号(表示语句与done的分割)。换言之,不可能有两个分号相邻。
关于变量
如果只是重复执行几个没有丝毫变化的语句,似乎有点“无趣”。但我们如何在命令中加入一些可以变化的东西呢?那就是变量。在Linux命令行当中,变量是以$符号表示的。例如,$i表示变量i。因此,如果我们希望一次性创建a到e五个目录,则可以使用下面的语句:for i in {a,b,c,d,e}; do mkdir $i; done。其中,for i in {a,b,c,d,e}表示遍历后面的列表,并分别将变量i赋值为列表中的元素;后面的语句表示执行mkdir命令,但其中的参数为变量i,例如,第一次时执行的为mkdir a,第二次就为mkdir b,以此类推。
在所有变量中,有一些变量是比较特殊的,它们具有特定的含义。比较常见的如$PWD表示当前所在的目录路径;$OLDPWD表示上一个所在的目录路径。
在一般的命令行中,你也可以在必要的时候使用这些命令(哪怕不是在循环中)。例如,echo $PWD表示打印当前路径2。(事实上,你也可以直接使用pwd命令快速实现这一功能)
特别注意的是,$OLDPWD表示上一个所在的目录路径,而不是上一级目录。例如,原先在1/a/目录下,当你使用cd 1/b/切换到1/b/目录时,变量$OLDPWD表示的是1/a/而不是它的上一级目录1/。使用cd $OLDPWD可以帮助你快速切换到上一个操作的目录,但还有一个更简单的方法是使用cd -,这二者是等价的。
就目前在写作的过程中,我还没有具体了解到如何在for循环中使用两个变量。类似于for i,j in {a,b,c},{1,2,3}这种写法是不可行的。如果你了解到了具体实现这一效果的方法(在命令行下),请通过前面的联系方式联系我。
seq序列
在前面使用for循环时,我们需要把遍历元素全部列举出来。通常这种方法适合于一些没有特定模式的序列,且数量较少。对于数量较多,或者我们明确知道其规律(通常是一些数字序列),一般会选择使用序列的方式让命令行自动生成。在Linux当中,最普遍的数字序列生成的方法是使用seq命令,其形式为seq <起始数值> <步长> 终止数值。当只有一个参数时,起始数值和步长默认为1;两个参数则分别表示起始数值和终止数值(此时步长默认为1)。
当希望在for循环中使用序列时,需要将seq命令(包括后面的参数)使用反引号(`)括起来。例如,for i in `seq 1 2 10`表示对序列{1,3,5,7,9}进行遍历。
正如你所见,seq 1 2 10表示序列{1,3,5,7,9}而不包括11,这是因为11超过了终止数值10.而对于seq 1 2 11则包括11.这一点可能与其他编程语言如Python不同,在Python当中,range(1,11,2)不包括最后的11.
seq命令可以使用负步长表示递减序列。例如,seq 5 -1 1表示序列{5,4,3,2,1}。
同时,seq也可以使用浮点数,例如,seq 0.1 0.1 0.5表示序列0.1到0.5,间隔0.1.
除此之外,对于一些整数的序列,也可以使用更简单的方式,其形式为{起始数值..终止数值..<步长>}。例如,for i in {1..10}表示对1到10进行遍历;而for i in {1..5..2}则对{1,3,5}遍历。
与seq不同的是,使用..的表示方法还可以对字母序列进行表示,例如,{a..z}表示所有小写字母,同理{A..Z}表示所有大写字母。
同样的,你也可以使用A..z对大写字母和小写字母进行表示,但此时还包括一些特殊字符如[,]等,它们是在ASCII码介于字母中间的部分(91到96)。
特别注意的一点是,使用..的方法不能对浮点数进行操作。当然,对于负步长仍然可用,例如,5..1..-1表示序列{5,4,3,2,1}。但对于这一方法,更特别的是你可以省略后面的步长(加上也不错),Linux会自动做降序。更甚者,你可以使用{10..2..2}的方法来生成{10,8,6,4,2}这一序列(此时步长完全是错误的)。
最后再来总结一下,对于整数序列,无论使用哪种方式都能得到;而对于小数(浮点数)序列,只能使用seq方法;对于字母序列则只能使用..方法生成。
一些for循环使用例
下面,讨论一些for循环的使用方式,仅供启发用(实际使用时可能需要根据实际情况进行个性化调整)。
首先,如果我们希望生成序列为{200,400,600,800}的目录,则可以使用命令for i in {200..800..200}; do mkdir $i; done。正如你所见的那样,这一命令表示对于这样一个序列进行遍历,执行mkdir命令,其中参数为变量i,依次为200,400,600,800(前面的序列)。
下面,假设我们在当前目录下有一个文件INCAR,希望将其拷贝至这里面每一个目录下,可以使用命令for i in {200..800..200}; do cp INCAR $i; done。其中表示对序列的每一个变量i,执行cp命令,其中参数(拷贝目标路径)分别设置为序列里的元素。
最后,当我们希望将每个目录里面的INCAR里面的ENCUT = 200分别改为ENCUT = [目录名],可以使用下面的方法:for i in `seq 200 200 800`; do cd $i; sed -i "s/200/$i/g" INCAR; cd $OLDPWD; done。这表示对前面的序列\footnote{这里我们使用seq方式生成,仅是为了多一种展示,也可以使用200..800..200,它们是一样的。},依次执行下面的操作:
- 进入其目录;
- 使用
sed命令修改(使用方法详见sed文本替换一节),其目标文本为变量$i,也就是目录名; - 返回到之前的目录(以便于能够继续遍历其他元素,进入对应目录)
你可以试一试,如果没有后面的cd $OLDPWD,会发生什么?稍加分析可以看出,当进入200目录时,修改完毕之后,会进入下一次循环遍历,此时尝试执行cd 400。但当前目录下并没有该目录(200和400是并列关系,不是父子目录关系),因此程序会报错。具体的报错可以看下面的简单for循环-错误处理一部分。
错误处理
-bash: cd: <目录名>: No such file or directory
这就是前面所说的忘记cd $OLDPWD的错误信息,此时会发现,没有目录,怎么办?只能报错了(如果你足够“机敏”,也许你会联想到目录操作一节。没错,在那里的目录操作-错误处理当中,也有这一错误。实际上,二者的本质是相同的。
seq: invalid floating point argument: <字符>
这是因为你在使用seq时尝试生成非数值(整数或浮点数)序列。例如,你也许本意是生成字母a到z的序列,但使用seq a z则会产生上面的错误。正确方法是使用{a..z}
使用..的方法生成浮点数,结果错误
使用..不能生成浮点数。因此,如果你希望生成浮点数,一种方法是使用seq,当然,还有一种“投机取巧”的方法,即尝试将浮点数用整数表示。例如,如果希望生成{0.1,0.2,0.3,0.4,0.5}的目录,除了使用for i in `seq 0.1 0.1 0.5`; do mkdir $i; done外,还可以使用for i in {1..5}; do mkdir 0.$i; done。其中0.$i的$i需要替换为遍历的序列(整数),也就是{0.1,0.2,0.3,0.4,0.5}。
第一个脚本
作者: Jiaqi Z.
知识点
- 什么是Shell脚本
- 如何编写第一个Shell脚本——Hello World
- 如何运行脚本
在前面的学习中,我们已经了解如何使用Linux命令在Shell进行操作,我们了解了如何对文件和目录进行简单的操作(如删除、复制等),同时我们也了解了一些更复杂的操作,例如使用grep和sed进行文本的查找和替换等。最后,我们还了解了如何使用for循环来进行批量操作。
而在一些特殊的场景下,我们可能希望做更复杂的操作,或者说,我们希望更简单地执行一些操作(这两句话本质上是一样的)。例如,如果我们每次都需要使用sed命令修改特定的内容,如ENCUT = 400,刚开始还好,时间长了可能就会“嫌麻烦”。此时可能就会希望有一个单独的命令(比如叫做changeENCUT)来实现这一功能。而实现这一功能的方法,就是使用脚本。
在本章,我们将会讨论如何编写自己的脚本。类似于编程语言,脚本里面将会包含大量的编程思想——如输入、输出、条件、判断、函数等。在学习这一部分之前,希望你已经有了部分编程语言基础(没有也没有关系)。
关于Shell和Bash的区别:一般来说,Shell指的是系统和用户交互的那层“外壳”,之前我们所学习的内容,其操作都是在Shell当中进行的。Shell具有多种版本,如“Bourne Shell”、“Bourne Again Shell”、“C Shell”等。其中,“Bourne Again Shell”就是我们所谓的“bash”。在你的操作系统下,可以使用top命令查看其Shell类型。
Shell脚本,全称叫做“Shell Script”,是一种在Shell当中批量运行多条语句的程序。
由于目前主流的Shell是基于Bash解释的,而我们所写的Shell脚本,实际上也大多都是Bash脚本,因此在后文当中,我们可能不会精确区分Bash脚本和Shell脚本的区别。
编写第一个脚本
正如任何程序的开始都是“Hello World”,在本章我们也不例外。在Linux当中编写Shell脚本不需要额外的程序,只需要使用vi编写一段文本文件,并赋予它运行权限,就可以作为脚本运行了。首先通过vi创建一个名为hello的文件,并输入如下内容:
#!/bin/bash
# 输出Hello World!
echo "Hello World!"
编写完成后保存,并添加运行权限(chmod +x hello,详见第文件权限管理一节),然后执行./hello,即可在屏幕上看到输出结果。
在运行时需要加上./表示在当前目录寻找命令。在Linux当中,不添加./表示在环境变量PATH下查找文件运行,你可以在家目录下找到.bashrc的文件,里面包含有一系列配置Bash的命令,其中就有对环境变量的设置。
在运行前,你需要保证程序已经具有运行权限,或者可以使用source ./hello或. ./hello的方式(二者等价)“临时赋予运行权限”1。
其中,代码第一行#!/bin/bash表示使用bash运行。正如前面所说的那样,Shell具有多种版本,因此,在编写时应当特别指定你所使用的版本。由于目前大多数Shell都是使用Bash,因此这一行在有些时候“可以省略”。但我们不建议将其省略,因为你永远不能保证你的这个脚本今后会在哪个版本的Shell下运行。
你可以想见,/bin/bash就是bash命令所在位置,你可以去看一下是不是真的存在。在查看的时候,注意是从“根目录”开始而不是“家目录”
如果你真的这么做了,一种简单的方法是在/bin/目录下使用ls | grep bash只输出具有“bash”的文件,从而简化输出结果。当然,你也可以直接使用ls bash查看。
当然,不建议你尝试使用vi bash查看里面的内容,它不是文本文件。
代码第二行以#开头表示注释。如同编写其他代码一样,使用注释是一个好习惯,它可以帮助你划分代码段落,以及记住对应的功能。随着学习的深入,我们会编写越来越长的脚本。因此,记得加注释是个好习惯。
第三行是这一脚本的关键,它使用echo实现字符串的输出。事实上,Shell脚本的每一个命令都可以在Shell本身下运行。因此,你也可以直接在Shell运行这一命令,会实现同样的效果。而编写脚本之后,就可以直接通过./hello实现这一功能,这便是脚本的作用。
echo会将它后面的所有内容输出(在其他一些编程教材中,会将这一功能叫做“应声虫”,实际上,echo也就是“回音”的意思)。我们在这里添加双引号是为了强调它们是整体的,事实上,当你去掉这两个双引号,对程序运行结果没有任何影响。
如果你在你的脚本中编写了代码,并同样使用了双引号,请注意:使用英文符号而不是中文符号,这一点在后续所有脚本编写过程中都应当注意。一般来说,我们不建议在脚本当中添加中文,虽然你写echo "你好,世界!"可能也会得到正确的结果,但不会永远如此。
在本章的教程中,为了考虑到读者水平,我们的注释部分都会采用中文,如果这样也会引起脚本运行的失败(在测试时正常,但不敢保证在你的电脑也会正常),请删除中文注释后运行。
添加至环境变量
正如前面所说,使用./hello表示在当前目录下查找名为hello的脚本并运行。这可以帮助我们快速调试代码,但在真正应用时,我们可能会希望在任何目录下运行脚本。此时就会希望将代码添加至环境变量,也就是前面所说的PATH。添加方法有两种——将脚本放置到已有的环境变量中,或者将脚本所在的目录设置为环境变量。
你可以通过$PATH命令输出当前环境变量,通常来说,你可以将你所编写的脚本命令放置在\texttilde/bin/目录下(这一般都是用户的环境变量)完成后,你可以在任何目录下运行你的脚本了(不需要./了)。例如,在完成上述配置后,在任何目录下运行只需要使用hello即可。
如果你编写了一系列脚本,一个简单的方法是直接将它们所在的目录设置成“环境变量”。此时需要通过.bashrc文件。假设你的脚本所在目录为\texttilde/bash/,使用vi打开.bashrc文件,在最后一行添加export PATH=$HOME/bash:$PATH即可。
其中,export是用来设置“环境变量”的命令,后面的PATH=...则是“变量赋值”的过程(后面就会学到)。$HOME是系统内置的变量,表示用户的家目录,你可以在Shell下使用echo $HOME查看变量的值\footnote{在这里我们又不知不觉接触到echo的新用法:输出变量的值。这本是后面的内容,在这里你可以提前先了解一下。},后面的$PATH则表示原先的环境变量。
简单说,这一语句的意思就是在原有的PATH变量前面添加一个新的$HOME/bash。添加完成后你需要使用source \texttilde/.bashrc命令“激活”这一环境变量(或者重启也可以实现这一功能),然后即可在任何地方如一般运行命令一样运行你在\texttilde/bash/目录下所有的脚本了。
在后面的教学演示中,我们都不会添加./运行脚本(或者说,只有在这一节我们会详细提到如何运行脚本,后面都简单说作“运行脚本”)。如无特殊说明,无论是哪种方法(在当前目录、添加环境变量),运行最终效果都是一样的,后面不再赘述。
为了你的方便,建议新建一个目录作为你后续练习脚本的目录,并使用上面的方法将其添加到环境变量中。
错误处理
-bash: <脚本名>: Permission denied
这可能是因为你在运行脚本时没有赋予其运行权限而直接运行脚本,如果你没有赋予权限,请使用source命令或.运行脚本。这同样适用于环境变量中的命令。对于环境变量中没有运行权限的脚本,需要使用source <脚本名>或. <脚本名>执行。
变量
作者: Jiaqi Z.
知识点
- 如何在脚本中定义变量
- 如何输出变量
- 如何对变量进行简单运算
如果所有脚本都只能按照固定的内容运行,显然功能太弱了。与其他编程语言类似,脚本语言应当也具有类似于“变量”的功能实现“可拓展性”。
所谓“变量”,指的就是在运行过程中会发生变化的量,这些值可能是由用户输入给定的,或者在运行过程中生成的,或者是通过文件读取得到的。
定义变量与初始化
与C语言等强类型语言不同,Shell脚本的变量在使用之前不需要对其进行“声明”,相对地则是需要对其进行初始化。与其他编程语言类似,在Shell脚本中,第一次使用变量时需要对变量进行赋值(也可以叫做“初始化”)。例如,我们希望将字符串“Hello World!”赋值给一个变量,则可以使用STRING="Hello World!"
与其他编程语言类似,在Shell脚本中,赋值也是使用=运算符。但不同的一点是,在运算符两侧不能有空格。
在变量命名时,需要遵守如下原则:变量名只能包括数字、字母和下划线(_),第一个字符不能是数字,不能是已有的关键字1。
在一个程序中,可以同时存在多个变量,对于已经赋值的变量,也可以对其再次进行赋值(原有值会发生变化)。例如,下面的代码:
#! /bin/bash
# 变量初始化
STRING1="Hello World!"
STRING2="I Like Bash"
STRING2="I Like Shell Script"
上述代码第3行定义了一个变量STRING1,其赋值为"Hello World!";在第4行,首先定义了一个变量叫做STRING2,首先赋值为"I Like Bash",在第5行又一次对其进行赋值,此时STRING2的值变为"I Like Shell Script"。
调用变量
如果你熟悉其他编程语言如C、Java、Python等,也许在编写上面的语句时,你会很自然写出如STRING2=STRING1这样的语句。在你看来,这好像是把STRING1的值赋值给STRING2,但当你运行时,发现事实并非如此。这是因为在Shell脚本中,变量的调用需要用到其他的方法。
在上面我们提到STRING2=STRING1的含义是将STRING1的值赋值给STRING2,这对于了解过其他编程语言的读者而言是很自然的。但如果你没有学习过其他编程语言,需要特别注意的一点是:在程序设计语言中(几乎大多数的程序语言),=所表示的含义与你所熟悉的数学上的含义不同。在数学上,=表示一种状态,表达两个值相等;而在程序设计中,=表示将右边的值赋值给左边的值(一种动作)。
尽管在最后的结果上,二者是相同的,但数学上的=表达一种“状态”,而程序设计中表达一种“动作”,是不同的。一个很简单的例子就是上面的STRING2=STRING1,从数学的角度看,这显然不成立,因为"I Like Shell Script"显然不可能等于"Hello World!",但程序设计上是可行的,因为它表达了“赋值”的动作。
也正因如此,在数学上,和相等写成或者都是可行的(这也就是等式的“对称性”);而对于程序设计而言,a=b和b=a显然是不同的,因为它们所表达的动作“方向”是不同的。
在Shell脚本中,调用变量需要使用到$符号。事实上,这不是你第一次见到它(如果你忘记了,请回到简单for循环一节,或者更准确的,简单for循环-关于变量一节)。与定义变量不同,在Shell脚本中,但凡是需要调用变量的地方,都需要使用$符号。例如,在上面的例子中,如果你确实希望表达STRING2=STRING1,需要写作STRING2=$STRING1。
这里有一点“小绕”的地方在于,为什么在STRING2前面不需要添加$符号。这是因为,我们实际上只是调用了STRING1变量的值,并不关心STRING2里面是"I Like Shell Script"还是"I Like Roselia"。因此,我们只需要通过$STRING1来获得STRING1的值。
你还可以做一个“不准确”的理解:$总是试图将右边的内容“展开”为完整的内容。例如,假设STRING2的值为"Hello World!",那么在调用STRING2=$STRING1时,可以写作STRING2="Hello World!"(将变量STRING1展开)
对于前面所介绍的for循环,其本质是类似的。例如,for i in {1..5}; do echo $i; done,实际上也是将变量i展开为具体的1到5.
当你了解这个时,对于后面的一些操作,会很有帮助。
在了解了如何调用变量后,我们就可以做一些完整的事情了。例如,下面的一段完整代码实现了变量的初始化,修改赋值和调用,并在最后使用echo语句进行输出。
#! /bin/bash
# 变量初始化
STRING1="Hello World!"
STRING2="I Like Bash"
# 修改变量的值
STRING2="I Like Shell Script"
# echo输出变量的值(调用变量)
echo $STRING1
echo $STRING2
运行上述代码,就可以看到输出了“Hello World!”和“I Like Shell Script”。
字符串中的$符号
像上面这样在字符串中使用$符号,最简单的情况就是上面这种单纯输出一个变量。但大多数时候,我们可能希望在输出时提供更复杂的内容。例如,我们有下面的变量
#!/bin/bash
# 初始化变量
name="Jiaqi Z."
band="Roselia"
如果我希望输出“My name is Jiaqi Z., and I like Roselia”。如果考虑到echo可以连续输出多个参数,也许你会想写出echo "My name is" $name", and I like" $band这样的语句。确实,从运行的角度,这个句子没有任何问题。但显然从可读性的角度,稍显复杂。那么,有没有更简单,更清晰的方式呢?
在使用$表示变量时,我们可以将变量名使用大括号将其括起来。例如,上面的例子,我们就可以写作echo "My name is ${name}, and I like ${band}"
如果你尝试将大括号去掉,在这一例子中,同样可以运行出正确的结果。这是因为,每一个变量名后面都跟着一个“标点符号”。如果对于再一般的情况,我们的变量名后面跟着另外一些字母。例如,如果我们在$name后面再加个s,对于使用大括号的情况,则会输出Jiaqi Z.s,而对于没有大括号的情况,则会输出错误的结果(由于没有变量叫做names)。
因此,为了更一般的情况,我们建议在使用变量名调用变量时加上大括号。
变量简单运算
在前面的例子中,我们都是针对于字符串变量进行讨论。事实上,变量还可以保存一些数值信息(例如整数、小数等)。例如,我们可以定义变量a=3和b=2.5。
同时,在脚本中,我们也可以进行简单的四则运算。简单的方式则是利用$ (( 表达式 ))的格式写出运算内容。例如,下面的代码则是简单计算1+1的结果:
#! /bin/bash
# 定义变量
a=1
b=1
# 计算
c=$(( ${a} + ${b} ))
# 输出
echo ${c}
在Shell脚本中,四则运算(加减乘除)的符号分别为+, -, *, /,同时需要特别注意的两个符号是%表示取余,即求得两个整数相除后的余数,例如,计算echo $(( 9%4 ))可以得到1;**(两个乘号)表示幂运算,例如,echo $(( 2**10 ))表示,即1024.
在Shell脚本中,你可以使用这种方法进行整数的四则运算。对于小数而言,则需要使用更复杂的方法。例如,对于变量a=1.5和b=2,如果希望做小数的四则运算,可以使用bc命令,写作echo "${a} + ${b}" | bc。
但对于脚本来说,通常你不应寄希望于它的运算功能(这主要由于运算效率的限制)。通常来说,对于需要使用复杂运算的任务,应当考虑其他效率更高的编程语言如C语言2和Python语言。
例如,上述问题如果希望使用C语言编写,则可以写作下面的代码:
#include "stdio.h"
int main()
{
double a = 1.5;
int b = 2;
printf("%f\n",a+b);
return 0;
}
并通过gcc calculate.c的方式编译代码,得到a.out可执行文件。通过./a.out即可运行得到正确结果。
正因如此,在本教程中,我们不会详细讨论脚本的计算(如果你确实需要使用脚本进行复杂运算,请查阅其他相关资料(例如bc和awk的相关使用方法)
错误处理
-bash: <表达式> : syntax error: invalid arithmetic operator (error token is "<表达式>")
这可能是由于你错误使用了四则运算符,例如,在使用$(())的方式进行计算时,要求只能进行整数四则运算。如果你的运算符两边出现了小数,则会出现错误。
bash: <变量名>: command not found...
这是因为你在对变量进行赋值时,在=两边加了空格。在Shell脚本中,赋值符号(=)两边不能有空格,这一点与其他编程语言不同。
输入
作者: Jiaqi Z.
知识点
- 如何读取用户输入
- 如何读取命令参数
- 如何将命令执行结果赋值给变量
在前面,我们仅仅讨论了脚本内定义的变量,这对于脚本而言远远不够。在实际使用脚本的时候,有一些信息只有在调用时才能知道。例如,如果我们希望编写一个可以删除文件的脚本1,在编写时不可能知道需要删除哪些文件。因此,有必要在写脚本时考虑实现“交互”。
通常来说,交互的方式有三种:程序运行时输入、程序调用参数、以及外部文件。在本节,我们将讨论这三种交互方式如何在脚本中实现。
严格来说,还有一种:管道输入。在本节我们不详细讨论管道的输入方式。
用户输入
在Shell脚本中,实现用户输入的方法是使用read语句。一般格式是read <变量名>,例如,read a表示在运行时读取用户输入,并将输入结果赋值给变量a。
在调用read命令时,可以提供一个选项,-p表示在屏幕上显示提示信息,其格式为read -p <提示信息> <变量名>。
利用这一命令,我们可以实现简单的交互。例如,我们可以写一个简单的“应声虫”小程序,即当用户输入一个内容后,程序原封不动将其输出。
#!/bin/bash
# 读取输入
read -p "Please input a string: " STRING
# 输出
echo "You said: ${STRING}."
echo "Good Luck!"
其中,第3行我们使用read命令读取用户输入,并将其赋值给STRING。之后在第5行使用echo语句输出了用户的内容(在前面加了一些其他内容)。
在运行时,程序会首先输出Please input a string: 并等待用户输入。当用户输入完毕后,按下回车表示完成,此时程序执行后面的内容(输出)。
在读取输入时,不要在变量名前面“画蛇添足”加上一个$符号。如果你试着这样做,会得到错误的结果——它有可能会输出空白信息,或者输出一些其他的内容。
输出空白或者其他信息取决于你的运行方式是使用source还是添加执行权限。对于前者,source本质上相当于在当前Shell终端下执行了脚本里的命令,其变量会延续到脚本外。因此,如果你在刚开始正确时输入了一个内容,如“Hello World!”,脚本会将其赋值给STRING变量并延续到Shell外部(用更专业的说法,这种“延续”实际上是“作用域”的体现)。此时如果你尝试在外面直接运行echo $STRING,也会得到对应的结果。
如果你是添加了执行权限并运行的话,脚本实际上是在当前Shell下新建了一个“子Shell”并运行,运行过程中产生的变量仅会在这一Shell内有效(表现为程序内),当退出脚本时,变量也就因此失效了。
在使用read输入变量时,如果后面加了$符号,则不会输入任何内容。此时在echo $STRING时,则会根据目前环境下已有的变量,输出对应的结果(已有的内容或空白)
参数输入
除了使用前面所介绍的read方法在程序运行时读取用户输入,在有些时候可能也希望通过类似于参数调用的方式输入。可以类比一下最开始我们所接触到的如cd和rm,在切换目录或者删除文件时,都是在调用时直接给出对应的文件名,而不是在运行过程当中输入。那我们有没有类似的方法实现这一功能?
答案肯定是有的,而且这一部分你不需要任何特殊的命令。因为在脚本中,如果调用时提供了一个参数,默认在程序中就是$1,以此类推,如果有两个或多个参数,则分别是$2, $3, $4等等。例如,下面的代码则实现了位置参数的调用:
#!/bin/bash
# 输出第一个参数
echo "First parameter is ${1}"
# 输出第二个参数
echo "Second parameter is ${2}"
当调用时,类似于之前使用其他内置命令那样,可以往其中传递参数(使用空格分割),如./loc_parameters hello world,则第一个参数为“hello”,第二个参数为“world”。
通常来说,我们将这种形式上如$n的参数叫做位置参数。也请务必注意的一点是:位置参数默认是从1开始而不是从0开始的。当参数数量在9个及以内时,可以直接使用$1到$9这种形式,但如果到了10个及以上参数,需要在数字外面加大括号如${10}。
你也可以尝试在程序中使用$0,它表示正在运行的脚本名称。
如果你真的尝试输出$0的值,可能会意外地输出一个叫做-bash的内容而不是脚本名称。这是因为如果你使用的是source方式运行,在这种情况下,你的脚本实际上是在当前命令行环境下运行,此时程序中的$0与你直接在命令行中输入$0运行结果应当是一致的。
另外,如果你的程序是在其他目录下运行(假设你已经将这一目录添加进环境变量),此时$0会输出这一脚本所在的完整目录。
除了直接使用位置编号表示参数本身外,Bash脚本还提供其他内置的参数表示其他信息。常见的例如$#表示传递的参数个数(不包括$0),$@表示整个参数列表。下面的程序使用for循环遍历了所有参数(完整的for循环教程在后面介绍)
#!/bin/bash
# 输出一些特殊参数
echo "Current file is ${0}"
echo "We have $# parameters"
echo "They are:"
for i in $@
do
echo $i
done
其中,第6行使用$@符号表示传入的参数列表,并对其中的所有元素进行遍历(输出)
读取命令作为输入
除了在运行时输入,在很多时候我们需要借助于一些命令读取文件的内容,并将其作为变量进行处理。例如,我们希望读取INCAR文件中的ENCUT所在的一行,根据前面所学习的方法,我们可以使用grep命令,如grep ENCUT INCAR命令来输出这一行。如果我们希望将这一命令作为变量输入到脚本中,只需要使用$(grep ENCUT INCAR)这种形式即可,其命令使用小括号,且前面加上变量的$符号。同样,在命令里面也可以使用变量以实现更复杂的交互功能,下面的代码实现了用户输入一个字符串和文件名,查找文件中包含这一字符串所在一行的内容:
#!/bin/bash
# 读取字符串
read -p "Please input a string: " STRING
# 读取文件名
read -p "Please input a file name: " FILE
# 读取命令并赋值
result=$(grep ${STRING} ${FILE})
echo ${result}
上述代码并不是一个“完美”的代码,因为在读取文件时,并没有对文件是否存在进行检查。因此,如果输入了一个不存在的文件名,则会输出错误的结果(如同你正常使用grep时输入了错误的文件名那样报错)。当你测试这一段代码时,请提前创建好一个对应的文件。
在后面的学习中,我们将进一步完善这一代码(设置一段代码实现文件是否存在的检查)
判断语句
作者: Jiaqi Z.
知识点
- 如何在脚本中使用
if及相关语句 - 如何对数值、字符串和文件进行判断
- 如何进行逻辑判断(与、或、非)
在之前的脚本中,我们只能按照顺序进行执行,从某种程度上来看,这并不“智能”。通常来说,一个好的脚本应该会根据实际情况来决定执行的内容,比如,当用户输入了一个文件名后,如果这个文件并不存在,程序应当做出相应的反馈。这一节,我们就会稍微了解以下如何进行判断,并且让程序根据情况做事。
if语句
在开始这一切的学习之前,让我们先来了解一个最基本的判断语句框架,以便在后面更好地讨论深入的话题。类似于C语言和Python语言等,在Shell脚本中,最简单的判断语句(if语句)框架如下:
commands1
if [ condition ]; then
commands2
fi
commands3
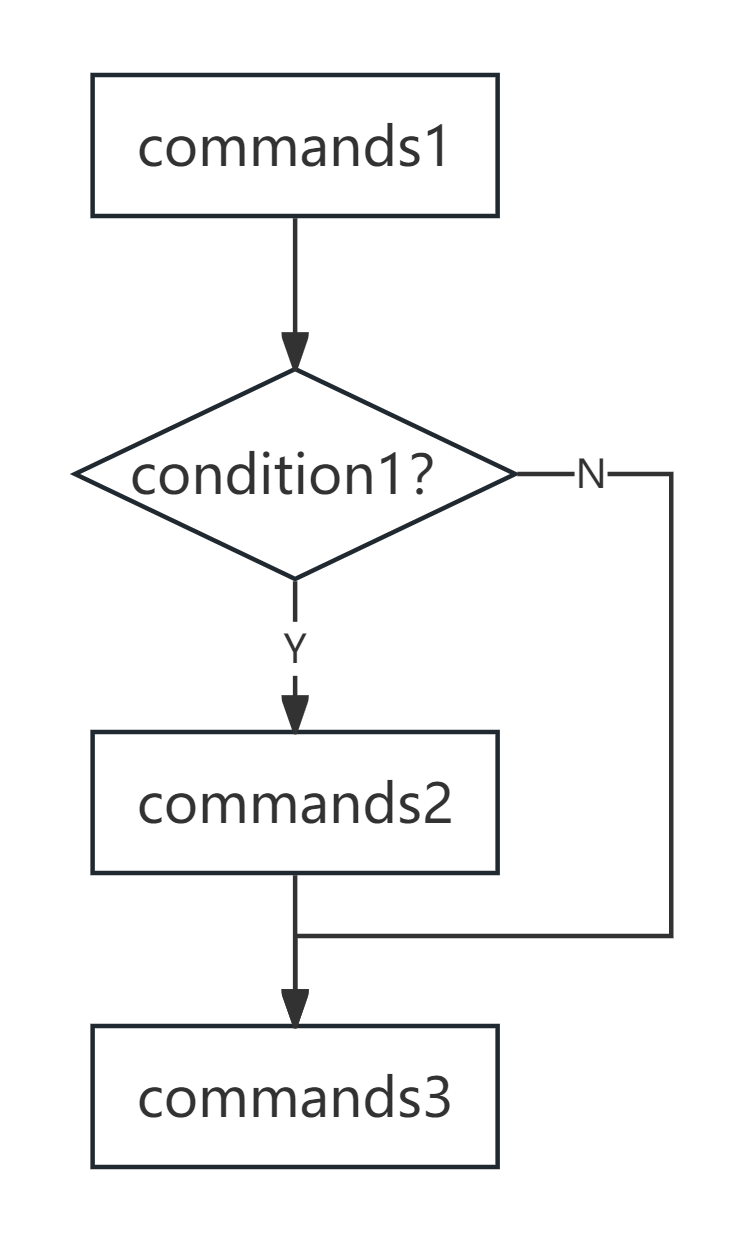
这一段代码当执行完commands1之后,进行condition判断(条件是否成立),如果(if)成立,然后(then)执行commands2语句,否则不执行任何语句,最后执行commands3。
无论条件是否满足,commands3都会执行(它是if语句之外的内容,类似于commands1)。在这里的commands1,commands2,commands3都代表语句(们),每一部分可以是一条或多条语句。condition是判断条件,在后面的部分我们将详细介绍如何描述这一部分,简单来说,它描述的内容就是“是否……?”。
需要特别注意condition前后与中括号之间的空格,这个空格不能省略!千万不要写成[condition]这种形式。
与C语言使用大括号,Python语言使用缩进不同,Shell脚本采用类似于Basic语言和MATLAB那样使用语句表示一整个语句块的方式。一个判断语句一定是以if开始,以fi结束。这个fi不代表“finish”或者“final if”等类似含义,而是if的倒序(在后面其他内容的学习中,会逐渐印证这一点)。
换言之,在上述代码中,使用缩进与否并不会影响脚本执行效果,但为了增强可读性,我们仍然建议使用缩进表示每一级之间的层级关系。事实上,如果你使用vi创建*.sh文件时,在输入if后默认会进行缩进,这也是大多数现代程序语言文本编辑器应当具有的功能。
关系运算符
任何一个分支判断语句,都应当首先给定一个关系运算,并根据这个结果来判断应该执行哪些命令。在Shell脚本中,我们大致可以将关系运算符分成三类:
整数比较
类似于数学上的大于、小于和等于,在Linux当中也有对数值的比较,包括等于(-eq, ==)、不等于(-ne, !=)、大于(-gt, >)、小于(-lt, <)、大于等于(-ge)和小于等于(-le)六种。
在Shell脚本中,许多运算符都是通过上面这种“选项”的形式给出。与一般输入命令类似,选项前后也需要有空格进行分割。
除了选项格式外,前四种(等于、不等于、大于和小于)我们也给出了类似于C和Python等其他编程语言所使用的运算符格式。这些在Shell脚本中同样可用。但是,对于大于等于和小于等于,没有>=和<=。如果你使用了这两个符号,大概率会报错。关于这一问题,目前还没有找到相关的解决方法,如果你有了对应解决方法(当然,不是后面要讲的内容),请联系我。
这些选项实际上是英文单词的缩写,例如,eq=equal; ne=not equal; gt=greater than; lt=less than; ge=Greater or Equal; le=Less or equal
在后面你还会见到其他类似的语句,了解它们的实际含义可以帮助你记忆这些选项。
下面的程序可以用来判断两个数字是否相等(使用前面的if语句)
#!/bin/bash
# 判断两个数字是否相等
a=10
b=10
# if语句判断是否相等
if [ $a -eq $b ]; then
echo "$a is equal to $b"
fi
# 判断结束后输出
echo "Bye!"
你可以试着修改变量的值,查看输出结果是否有不同。在上述代码中,当变量相等时,判断结果为“1”,从而执行里面的语句;如果不相等,则判断结果为“0”,跳过里面的语句。无论结果如何,你都会看见第10行所输出的“Bye!”(它在if语句外面)。
在这里我们提到了“1”和“0”,它们实际上叫做“布尔值”或者“逻辑值”,也是关系运算(与后面要提到的逻辑运算)的返回结果,其值只包含两种:“真”(也可以用“True”、“1”等代替)和“假”(也可以用“False”、“0”等代替)。
在中括号里面表示条件判断时,请务必记得中括号内前后要加空格,同时-eq前后也要加空格。
在完成if语句后,不要忘记后面的fi。
你也可以试着修改判断条件,例如改成-gt,并修改变量的值,查看结果。
*浮点数比较
由于前面所介绍的浮点数在脚本中的局限性,这一部分内容关于浮点数的比较并非必须了解。但如果你确实有此方面需求,在确定不能使用其他如C和Python等编程语言实现的前提下,可以参考这一部分所介绍的方法。
相比于前面的整数比较,浮点数比较不能使用前面的“选项”格式。例如,你写出if [ 3.5 -ne 2.5 ]是错误的。但是,前面所使用的运算符形式如==, !=等还是可用的。基于此,对于判断等于和不等于(包括大于和小于),最简单的方法就是使用如if [ 3.5 != 2.5 ]的格式。
但是,对于大于等于和小于等于这两种情况,整数部分尚且还有选项可用,浮点数则完全没有对应的简单方法。参考前面变量-变量简单运算一节所介绍的bc命令,我们可以退而求其次,借助于逻辑运算符的输出结果1和0,来进行判断。例如,我们希望判断3.5是否大于等于2.5,则可以使用if [ $(echo "3.5 >= 2.5" | bc) -eq 1 ]这种方式,其中小括号部分借助管道运算符和bc命令计算3.5 >= 2.5的结果,根据前面所介绍的逻辑值,输出结果应当是0或1(在这里为1)。然后利用整数的判断方法,判断它与0或1的关系,从而实现浮点数对大于等于和小于等于的判断。
字符串判断
与数值判断类似,字符串也可以进行相应的判断,一般常见的包括判断两个字符串是否相等(==),是否不相等(!=),以及判断一个字符串是否为空字符串(-z和-n)
在判断是否为空字符串时,可以使用-z和-n,二者在本质上判断的内容是一样的,但返回结果相反,前者当内容为空时返回“真”,后者当内容不为空时返回“真”。借助于后面的“求非”运算,这二者只需要有一个即可,但为了简洁易读,还是建议在对应的时候使用正确的关系运算符。
此外,与前面数值判断不同,判断字符串是否为空是“一元运算符”,即只需要一个变量。后面的代码则给出了这种一元运算符的一般格式。
下面的代码实现了判断一个字符串是否为空字符串:
#!/bin/bash
# 判断字符串是否为空
read -p "Please input a string:" string
# -n当字符串不为空时为真
if [ -n "$string" ]; then
echo "Right! I got something ..."
echo "You input: $string"
fi
echo "Bye!"
上述代码第5行通过-n判断输入字符串是否不为空,如果有内容(结果为真),则执行if语句里面的内容。
在对字符串进行判断时(包括使用二元关系运算符),请务必将字符串变量前后加上双引号。如果不加双引号可能会造成奇怪的错误。
文件判断
Shell脚本也提供了大量的运算符选项,用来判断文件的相关信息。例如,使用-e判断文件是否存在,使用-f(-d)判断是否为普通文件(目录),使用-r, -w, -x依次判断文件是否可读、可写、可执行。
与前面字符串的代码类似,这里的所有运算符都是一元运算符(即采用<选项> 变量的格式。例如,下面的代码简单实现了判断文件INCAR是否存在的功能:
#!/bin/bash
# 判断文件INCAR是否存在
if [ -e "INCAR" ]; then
echo "This file exists."
fi
echo "Bye!"
其中,-e后面的"INCAR"是指当前运行目录下的INCAR文件,你也可以使用绝对路径来描述文件。
带有else的判断语句
下面,我们将进一步介绍if语句,在之前我们仅仅用来判断某一个条件是否满足,且当满足时执行某一(些)语句。但有时,我们可能有更复杂的需求。例如,判断某一个文件是否存在,如果存在则对文件进行处理,如果不存在则输出文件不存在,并提示用户重新输入。我们姑且忽略到继续输入这一动作(需要用到后面的循环),当条件不满足时如何执行另外的语句?类似于其他编程语言,在Shell当中也可以使用if-else语句。其基本格式如下:
commands1
if [ condition ]; then
commands2
else
commands3
fi
commands4
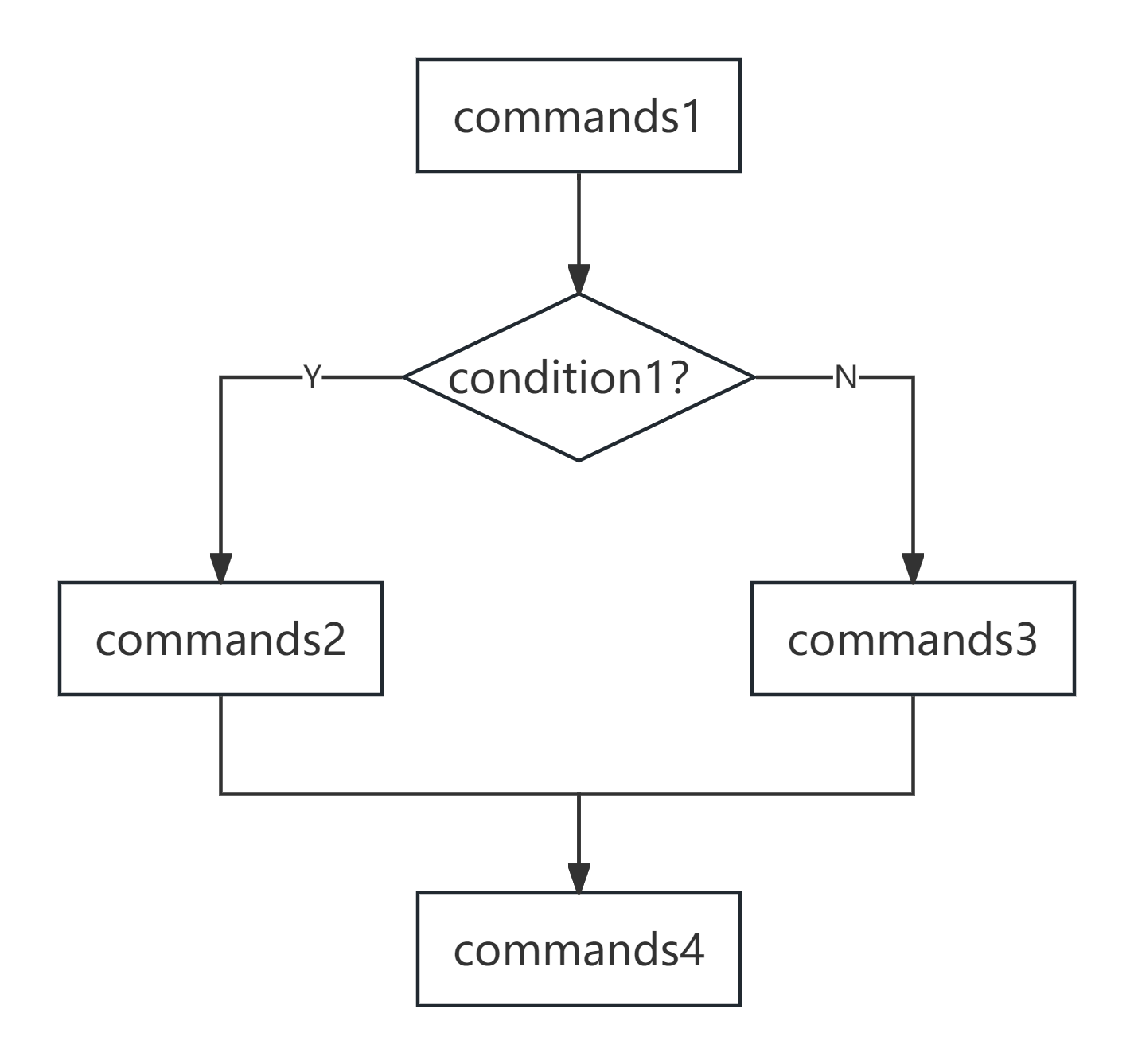
首先程序会执行commands1,然后进行判断,如果(if)条件成立,则(then)执行commands2,否则(else)执行commands3。 无论结果如何,最后执行commands4。
下面的代码则是利用上面的语法结构,对前面的判断文件是否存在的脚本进行了修改:
#!/bin/bash
# 判断文件INCAR是否存在
if [ -e "INCAR" ]; then
echo "This file exists."
else
echo "This file NOT exists."
fi
echo "Bye!"
此之外,与Python语言类似,Shell脚本也有if-elif-else语句,用来对多条件进行判断,语法如下:
commands1
if [ condition1 ]; then
commands2
elif [ condition2 ]; then
commands3
elif [ condition3 ]; then
commands4
……
else
commands5
fi
commands6
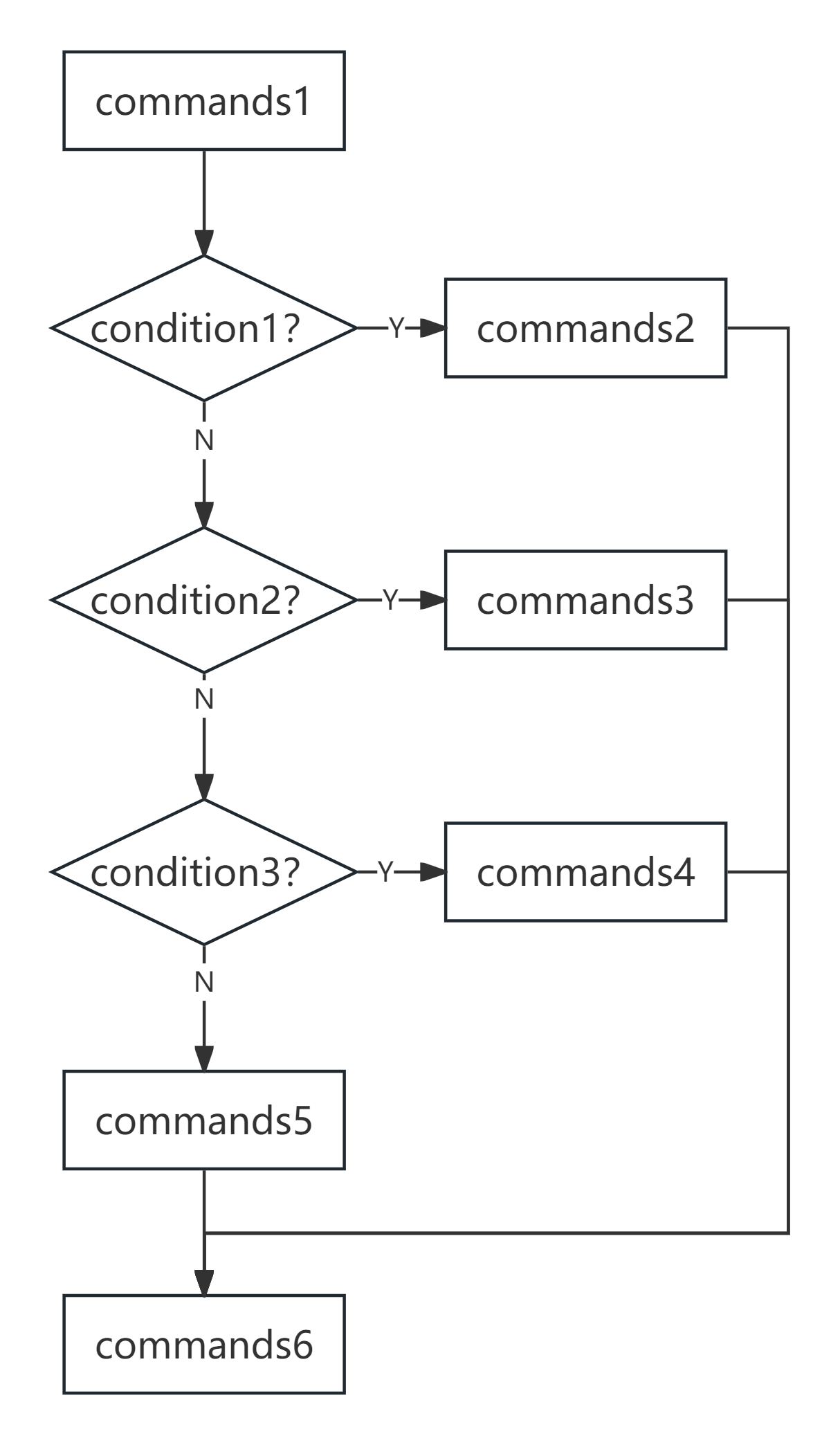
程序首先判断condition1是否满足,如果(if)满足,则(then)执行commands2并结束判断语句,反之如果(else if, elif)满足condition2,则(then)执行commands3并结束判断语句;反之如果……;否则都不满足(else),执行commands5。在结束判断语句后,执行commands6。
下面的程序可以用来判断两个整数之间的关系:
#!/bin/bash
# 判断两个整数之间的关系
# 输入两个整数
read -p "Please input an integer(a): " a
read -p "Please input an integer(b): " b
# 判断两个整数之间的关系
if [ $a -eq $b ]; then
echo "$a = $b"
elif [ $a -gt $b ]; then
echo "$a > $b"
else
echo "$a < $b"
fi
echo "Bye!"
嵌套if语句
与其他编程语言类似,脚本也可以使用嵌套的if语句,甚至可以更复杂的if-elif-else嵌套,基于此可以实现复杂的功能。在这里我们不举例子,但有一个需要特别注意的地方:
任何一个if语句,其后面都需要配合一个fi作为语句结束。尤其是对于嵌套时的if-else匹配问题,else总是与最近的未完成的if语句匹配(与缩进无关)。例如,下面的代码就违反了第一个原则(if必须配合有一个fi);同时,看似else是属于condition1所对应的判断,但事实上是属于里面的if。
if [ condition1 ]; then
commands1
if [ condition2 ]; then
commands2
else
commands3
fi
这段代码是无法正常运行的。所缺少的fi可以加在commands2后面,也可以加在commands3后面,二者所实现的效果是不一样的。你可以尝试一下不同位置所对应的程序运行结果。
逻辑运算
在这一节的最后,让我们再来讨论一下逻辑运算。逻辑运算一共分为三种:与(-a)、或(-o)和非(-n)。其中与运算和或运算都是二元运算符,而非运算是一元运算符。
对于与运算而言,只有当两个值都为真时结果为真。而对于或运算,只要有一个为真,结果为真1。对于非运算,是一元运算符,其运算结果就是真变假,假变真。
下面一个例子实现了判断三个数字是否从小大大排序:
#!/bin/bash
# 判断三个数字是否从小到大排序
a=5
b=8
c=10
# 使用与运算符连接
if [ $a -le $b -a $b -le $c ]; then
echo "$a, $b, $c"
fi
在这里我们使用多个运算符进行连接,与其他编程语言类似,这里也具有“优先级”的问题。可以简单的理解:关系运算符的优先级高于逻辑运算符的优先级(这在大多数编程语言中都是如此)。虽然上面的写法比较简单,但对于条件复杂的时候可能不具有较好的可读性。因此,可以使用类似于C语言的运算符(&&表示“与”,||表示“或”),而中间每一个条件使用中括号分割,写作if [ $a -le $b ] && [ $b -le $c ]
错误处理
这一部分有可能出现的错误太多了,以至于难以在这里全部列出。这里仅列举一些常见的错误,且这些错误的解决方法仅是一部分可能的原因。当你出现错误时,请首先查看对应的格式是否正确,并且可以尝试联系我们。
-bash: <文件名>: line <行号>: syntax error: unexpected end of file
这是因为在使用if后没有对应的fi作为结束。通常出现在嵌套语句中或者一个if语句太长,到最后忘记了匹配。对此,我们建议,在开始就按照if-fi对应关系输入。
bash: [<变量>: command not found...
这可能是由于你在输入关系表达式时忘记了中括号里前后要加空格。
-bash: [: missing `]'
与前面的错误类似,这个通常指右中括号前面没有空格。
case分支语句
作者: Jiaqi Z.
知识点
- 如何使用
case语句实现分支判断
在前面的if语句中,已经了解了如何进行判断。理论上了解了if语句后可以解决所有分支情况,但是有一些情况可能比较特殊。例如,我们希望实现一个菜单界面,此时可能需要用户输入一些指令表示对应的功能。可以想见,如果使用if语句,将会有许多的判断条件,甚至随着条件的增多,也会影响程序运行效率1。
因此,我们希望可以寻找一种方法,直接对变量进行判断,并根据它的值选择合适的语句执行。可以猜到,这就是本节case语句所要解决的问题。
case语句基本结构
类似于if判断语句,case判断语句的基本结构为:
case <变量> in
pattern1)
statements1
;;
pattern2)
statements2
;;
......
*)
statements3
;;
esac
程序会根据变量所在(in)的模式(可以是一个单独的值,或者正则表达式),选择合适的语句进行执行。例如,如果变量满足pattern1,则会执行statements1语句;如果满足pattern2,则会执行statements2语句;以此类推,如果所有的都不满足,则执行*所对应的statements3语句。
有几个细节需要特别关注:所有匹配模式都是以小括号作为结束分割(没有左括号);当每一个分支里面的语句结束时,需要有;;作为结束的标志;在case语句结束时,需要有esac作为结束标志。
正如在判断语句中所讲的那样,esac也是case的倒序。另外,模式当中的*实际上可以想见,表示的就是通配符里面的可以表示任意多个字符的*符号。
case语句应用
下面让我们来看几个常见的应用例子。
单一字符匹配
在case语句中,最简单的就是对单独一个字符进行匹配。下面这个例子则实现了一个对菜单的模拟,用户通过输入1或者2来实现对应不同的功能。
#!/bin/bash
# 模拟菜单选项
echo "--------------------"
echo "1) option 1"
echo "2) option 2"
echo "--------------------"
read -p "Please input a number: " number
case $number in
1)
echo "You input 1"
echo "I will do something for option 1..."
;;
2)
echo "You input 2"
echo "I will do something for option 2..."
;;
*)
echo "You did NOT input 1 or 2"
;;
esac
echo "Bye!"
运行上面的代码,可以看见:当用户输入1时,程序可以直接跳转到1)所对应的语句;对应的,当用户输入2时,可以跳转到2)所对应的语句;如果输入其他内容(例如输入3),则会跳转到最后提示输入错误。
与if语句类似,case语句的前后,即开始的提示和后面的“Bye!”无论哪种情况都会输出,因为它们不属于case语句内。
字符串匹配
字符串匹配与单一字符匹配完全一样(你可以将单个字符理解成一种特殊的字符串)。但是,在这里我们也有一点新东西要讲。如果我们希望多个选项匹配同一个分支,可以使用|符号表示“或”进行分隔。例如,下面的程序则是根据用户输入的字符串选择特定的分支(有时多个输入对应同一个分支):
#!/bin/bash
# 字符串匹配
read -p "Please input you favourite band: " band
case $band in
"PPP"|"ppp"|"Poppin'Party")
echo "Thanks! I have known that you like Poppin'Party!"
;;
"Roselia"|"R")
echo "Thanks! I have known that you like Roselia!"
;;
"RAS"|"RAISE A SUILEN"|"Raise a suilen")
echo "Thanks! I have known that you like RAISE A SUILEN!"
;;
"MyGO!!!!!"|"mygo"|"mygo!!!!!")
echo "Thanks! I have known that you like MyGO!!!!!"
;;
*)
echo "Sorry...I don't know this band."
echo "But now I have known it -- $band"
echo "Thank you!"
;;
esac
echo "Bye!"
与前面的代码分析完全类似,但特别的是,这里面分支的判断使用|表示“或”,例如,“PPP”、“ppp”和“Poppin'Party”对应的都是同一个分支;类似地,“R”和“Roselia”也是对应同一个分支,当用户输入“R”或者输入“Roselia”时,得到的结果是一样的。
正则表达式匹配
正如一开始所说的那样,在匹配时可以使用正则表达式。例如,下面的代码试图读取用户输入的参数为字母还是数字2:
#!/bin/bash
# 读取调用时的选项
export LC_ALL=C
case $1 in
[a-z])
echo "You input a lowercase"
;;
[A-Z])
echo "You input an uppercase"
;;
[1-9])
echo "You input a number"
;;
*)
echo "You input other things"
;;
esac
echo "Bye!"
也许你足够灵敏,注意到了第3行的export LC_ALL=C,这句命令表示将程序运行语言环境设置为默认值(可以通过locale查看环境语言设置),其中C表示系统默认值。
在这里我们需要添加这一行命令以确保程序运行正确,但这行命令并不影响我们对case的理解。
同时,当你运行这一行代码之后,可能程序中的中文注释发生乱码,这并不影响程序运行结果,你可以重新启动系统以恢复开始的状态。
在调用时,当用户传递给一个小写字母时,则会匹配到[a-z],相对地,若给定一个大写字母作为参数,则会匹配到[A-Z]。但是,我们这里只能对用户输入的一个参数进行判断,如果用户输入多个字符的参数(例如abc),程序则会认为输入了其他内容。如何修改程序呢?请自己思考并尝试写一段代码3,同时自己测试它。(为简单起见,我们只需要匹配第一个字符即可)
同时,正则表达式也可以使用|作为分隔以进行多个情况的判断,例如,我们希望将上面的代码修改为无论大小写字母都判断为字母,则可以写成下面的样子:
#!/bin/bash
# 读取调用时的选项
export LC_ALL=C
case $1 in
[a-z]|[A-Z])
echo "You input a letter"
;;
[1-9])
echo "You input a number"
;;
*)
echo "You input other things"
;;
esac
echo "Bye!"
错误处理
-bash: <文件名>: line <行号>: syntax error near unexpected token `)'
这可能是因为你在结束分支时少了;;表示当前分支内结束。如果你了解C语言,你可能会很自然将这这个符号作为C语言中switch-case的break语句。但显然,C语言的break更加灵活(它可以没有从而越过其他分支),但Shell脚本不能没有;;结束。
-bash: <文件名>: line <行号>: syntax error near unexpected token `<字符串>'
这可能是由于你在使用case语句后忘记结束esac而后面还有其他语句从而报错。如果后面没有语句,则可能会出现下面的错误:
-bash: <文件名>: line <行号>: syntax error: unexpected end of file
这也表明你可能没有使用esac作为case语句的结束。
循环
作者: Jiaqi Z.
知识点
- 如何使用
for循环 - 如何使用
while循环 - 如何使用
until循环 while循环和until循环的区别
在前面介绍高级Linux命令时,我们曾说过脚本处理的任务大多是批量处理任务,而批量处理的一个基本方法就是使用循环语句(毕竟没有人会想写上上百行相同的代码)。在简单for循环一节中,我们介绍过for循环的使用,当时是在命令行中编写的。本节我们将首先复习一下for循环的基本使用方法,以及它在脚本程序中的格式(和命令行类似),然后再介绍两种不同的循环语句——while循环和until循环——它们虽然在一定程度上是等价的,但在不同的情况下,选择合适的循环语句会让程序更加简洁易读。
for循环
下面的代码完整演示了常见的三种for循环格式:
#!/bin/bash
# 使用for循环输出
# 简单列表
for i in 1 2
do
echo $i
done
echo ""
# 生成列表
for i in $(seq 1 2 10)
do
echo $i
done
echo ""
# 使用C语言格式
for ((i=0;i<10;i++))
do
echo $i
done
其中第8行、第14行使用echo ""输出一个空行用来区分不同的输出结果。
简单列表
使用基本列表的格式调用for循环的基本格式为:
for <变量名> in <列表>
do
循环体
done
在循环语句内部的语句,我们常常称其为循环体(实际上和前面所说的commands,程序块,语句块等一样)
在这里的<列表>可以如同上面的代码一样直接以空格分隔表示,也可以与简单for循环一节所说的那样使用大括号将其括起来,并用逗号分割。
一个常见的错误是将两者混淆,即使用大括号表示列表的同时,其内部元素用空格分隔。可以验证的是,这并不会如你所愿得到正确的信息。事实上,空格的“优先级”会高于大括号的“优先级”(这里加引号表示这不是传统意义上运算符的优先级),当括号和空格同时存在时,程序会将列表解析为以空格分隔的列表,从而在输出的前后(第一个元素和最后一个元素)带有大括号。
与前面的介绍类似,在循环体内使用变量需要加$符号。
生成列表
与简单for循环里所介绍的方法类似,可以使用seq命令生成序列。与前面所介绍的方法不同的是,前面所使用的是`符号括起来的命令,而在脚本中,由于将seq看作是一个命令,因此与前面输入-读取命令作为输入一节所介绍的输入方式类似,使用$()的方式得到seq命令的结果,并将其作为一个变量传递给for循环。
当然,也可以使用前面所说的..的方式生成序列。但需要复习的是:对于seq语句而言,三个参数分别是开始、步长、结束;而对..方式而言,三个参数分别是开始、结束、步长。因此,上面代码的seq 1 2 10也可以写作{1..10..2}
运算格式生成
如果你熟悉C语言的话,这一种格式会显得很“亲切”。因为它的基本结构与C语言几乎完全类似,类似地写法,如果让我们用C语言实现上面代码的第3部分,则可以写作这样:
#include <stdio.h>
void main()
{
for (int i=0;i<10;i++)
printf("%d\n",i);
}
可以看到,相比于C语言,脚本只是一个括号和两个括号的区别1。
在脚本的for循环当中,括号前面没有$符号,也千万不要“画蛇添足”加上这个符号。
while循环
与C语言的while循环类似,在bash脚本中也存在根据条件判断循环与否的while循环。其基本格式如下:
while [ condition ]
do
循环体
done
其中,condition表示循环进行的条件,其格式与判断语句当中所介绍的条件表达式类似。例如,下面的代码实现了从0到9的输出
#!/bin/bash
# 使用while循环输出数字
i=0
while [ $i -lt 10 ]
do
echo $i
((i++))
done
可以复习一下,条件-lt表示小于,因此,循环体进行的条件是变量i小于10。当条件满足时,程序进行循环体(do和done中间的部分)。因此,程序会从0开始,逐渐输出并加1,直到条件不满足时(i为10)则停止循环。
与for循环相比,while循环更有可能写出“死循环”语句。所谓“死循环”,指的是程序在循环体内一直循环,永无停止。在上面的代码中,如果少了那句((i++)),则变量始终为0,条件始终满足,从而无法停止。
具体的解决方法,可以见下一节所介绍的break和continue语句。
在实际操作中,如果出现死循环导致程序无法停止,则可以使用Ctrl+C快捷键终止当前命令。
此外,在上面程序的第7行,使用((i++))表示进行计算,这是比较简洁的C风格递增运算符,类似的还有递减运算符--。这种方式的使用需要以两个括号括起来。你也可以使用变量一节所介绍的方法,使用i=$(( $i + 1 ))的方式。这二者在这一功能上是等价的。
until循环
与while循环几乎完全类似,bash脚本中until循环的格式为:
until [ condition ]
do
循环体
done
与上面的while循环格式比较可以发现,除了关键字从while变成了until外,其他语句在格式上没有任何不同。但until循环的最大特点是:循环体执行的条件是condition为假,即你可以简单的将其理解为:循环体会一直执行,“直到”(until)条件为真。
这一点稍微有点绕,但上面的两种表述是“等价”的。对while循环而言,当条件为真时执行循环体,而对until循环而言,当条件为真时退出循环(当条件为假时进入循环)
在C语言中,确实没有类似的循环与其对应,但我们可以从其他一些编程语言中找到这个例子,一个最简单的例子就是——Visual Basic语言(简称VB语言)。在VB语言中,也存在类似的until循环,其格式为:
Do
循环体
Loop Until 条件
如果你熟悉VB语言的话,bash脚本的until循环与VB语言的until循环最大的不同在于VB语言的条件是放在循环后面(类似于C语言的do-while循环)
当然,如果你不熟悉VB语言的话,也不必担心。这一部分仅仅是对那些熟悉VB语言的读者所准备的,以防他们混淆条件的位置。如果你本来不了解VB语言的话,这一部分完全可以跳过。
可以简单想见的是,while循环和until循环之间的转换仅仅是“条件的取反”,例如,上面关于while循环的例子,我们只需要将里面的条件$i -lt 10改为$i -ge 10,同时将while改为until就可以实现相同的功能。这一部分代码我们不做演示,请自己尝试修改上面的代码并测试其输出结果是否与之前的结果一致。
循环控制
作者: Jiaqi Z.
知识点
- 如何使用
break语句 - 如何使用
continue语句
在循环一节中,我们曾简单提到了“死循环”问题。在当时看来,死循环是一个应当避免的“错误”,但事实可能不总是如此——在有些情况下,我们可能不得不希望使用死循环。例如,我们希望一直读取用户的输入,直到用户输入0时退出。此时当然可以使用while循环或者until循环来解决这一问题。但还有一种思路——设计一个死循环,当用户输入0时跳出循环。
在其他领域,死循环可能是更常见的。例如,在一些单片机系统中,会使用死循环来执行对应的任务,例如读取传感器数据、显示处理数据等;而在Windows操作系统中,任何一个窗口在创建时都会启动叫做“消息循环”的死循环来保持窗口——对于Windows来说,如果没有这个死循环,窗口会立即关闭。
因此,在程序中,死循环并不是“绝对的错误”,而要根据需要选择。一些可控的、必需的死循环也是程序所必要的一部分。
回到最开始的例子,在bash语言中,我们有两种方式对循环语句进行控制——break语句和continue语句。其中前者表示“终止循环”,而后者表示“继续循环”
使用break停止循环
本节所要介绍的break与continue,在使用方式与效果上与C语言的break和continue完全相同。因此,如果你足够熟悉C语言,本节完全可以跳过。但我们还是建议你通过阅读这一节复习一下相关的内容。
break语句的作用是用来跳出循环,例如,下面的程序,用户输入一系列数字,当用户输入0时,循环结束,输出“end”
#!/bin/bash
# break跳出循环
read a
while [ true ]
do
if [ $a -eq 0 ]; then
break
fi
echo $a
read a
done
echo "end"
在第4行,我们设置了一个条件true,使循环条件始终成立,从而令其成为一个“死循环”。在第6行利用if语句判断输入的变量是否为0,如果是0,则通过break跳出循环,执行最后一行的“end”输出。如果输入的数字不为0,则输出对应的变量值。
请务必仔细思考一下,程序的第10行又写了一句read a有什么作用?如果没有这句命令会发生什么?在程序中有两句read命令稍显繁琐,有没有简单的方法使用一句即可实现相同的功能?
除了在while循环外,for循环和until循环也可以使用break语句。例如,下面的程序遍历了10-20之间所有的数字,且当数字为7的倍数时停止。
#!/bin/bash
# 在for循环中使用break语句
# 当遍历到7的倍数时停止
for i in {10..20}
do
if [ $(( $i%7 )) -eq 0 ]; then
break
fi
echo $i
done
echo "end"
其中,变量i会依次从10递增到20,当i取值为14时,满足7的倍数1,从而进入条件判断内,执行break命令,跳出循环输出end
上面的两个例子还说明了,break跳出循环是“立刻跳出”,即如果循环体内有剩下的其他语句也不会执行了。例如,上面的判断倍数的例子,当i取值为14时,也没有输出这个值(因为输出命令在break后面。
可以尝试一下:如果将echo $i放在循环体内第一行,输出结果会有什么不同?
使用continue跳过循环
与C语言类似,在bash脚本中,也可以使用continue跳过循环。这里所说的“跳过”,指的是跳过当前轮次的循环。让我们直接来看一个例子——假设将上面判断7的倍数的例子中的break改成continue,看看会发生什么。
#!/bin/bash
# 使用continue语句跳过循环
for i in {10..20}
do
if [ $(( $i%7 )) -eq 0 ]; then
continue
fi
echo $i
done
echo "end"
运行后可以看见,程序输出了10-20的所有数字,除了14。这是因为当变量i为14时,条件满足,执行continue语句,跳过了当前轮次的循环,直接进入下一个循环轮。与break类似,这里也不再执行后面的语句(即不会输出14这个数字)
虽然continue在语法上和break类似,难度也不大,但其使用时存在一个非常潜在的“隐患”。让我们再来看一下本节最开始的程序,如果将其中的break改成continue,会发生什么?此时代码长成下面这样:
#!/bin/bash
# 使用continue跳过0的判断,继续输入?
read a
while [ true ]
do
if [ $a -eq 0 ]; then
continue
fi
echo $a
read a
done
echo "end"
一些“粗心大意”的人可能会认为:这段代码一直读取用户的输入并输出对应的内容,当用户输入0时跳过输出。让我们执行一下这段代码,当用户输入非0的数字时,程序很正常地输出对应的数字;当用户输入0时,程序也确实跳过了0的输出;但是,从这开始程序再也读取不了输入了。从程序代码的执行过程可以很容易理解这一点,当用户输入0时,此时变量a的值为0,进入条件判断内,跳过当前循环。正如前面所说的那样,程序跳过循环不再执行后面的语句。因此,在后面的循环中变量a始终保持0的值,即始终在4-7行语句间循环。
对于for循环而言,由于它是对序列进行遍历,一般情况下总是“有限”的,因此循环总是能停止的。而对于while和until循环而言,在循环开始和continue中间,要有改变循环条件或者终止循环的语句,否则循环将陷入“死循环”。
*函数
作者: Jiaqi Z.
知识点
- 如何定义与调用函数
- 函数参数
- 函数返回值
前面我们已经学习了程序的基本结构——顺序语句、条件语句和循环语句。此时,应当已经足够完成大多数脚本程序的编写。在本节和下一节,我们将介绍一些扩展性的内容——函数和数组。这两部分可以帮助你更快、更方便地编写程序。
定义函数
在bash脚本中,函数的定义必须在调用之前。这是因为脚本语言是按照顺序执行的,如果在程序不知道的情况下直接调用,那必然会报错。在bash脚本中,对一个函数定义的基本格式为:
[function] function_name()
{
函数体;
[return int.;]
}
在定义时,可以在前面加上function以示区分,也可以不加直接以函数名作为开始。在函数内部的语句块使用大括号括起来(函数体),在函数的结束可以使用return语句返回一个范围在0-255之间的整数。
与大多数程序语言不一样,bash脚本对函数返回类型有明确的数值要求,且这个要求是不随程序员所改变的。如果要返回函数运行结果是否成功,可以使用return语句,但如果返回的是其他内容(例如返回两个数字相乘的结果),则可以使用字符串的形式返回。
在bash的函数定义中,我们不会在函数开始的地方强调参数的个数和类型(这点与C语言等类似语言不同),具体的参数将在函数体内部使用${num}的形式体现(与输入-参数输入所介绍的参数类似)
例如,下面的程序简单定义了一个名字叫做my_echo的函数:
#!/bin/bash
# 定义函数
my_echo()
{
echo "Hello"
}
这个函数内部只有一个输出语句,且没有返回值。
我们这里所说的“没有返回值”,特别指的是不使用return返回的返回值。你也完全可以将这个函数的echo输出看作是一个字符串返回。
有参数函数的调用
与输入-参数输入一节所介绍的方法类似,在函数内部我们也可以使用$1表示第一个参数,当参数个数大于等于10时,则需要使用大括号将数字括起来,例如,${10}表示第10个参数。
在函数体内部,我们也可以使用$#表示参数的个数(与前面所介绍的方法一样),可以使用$*将所有参数以字符串的方式输出。例如,下面的程序就实现了两个整数相加的计算函数:
#!/bin/bash
# 两个整数相加
function add_function() {
c=$(( $1 + $2 ))
echo $c
}
这里的第4行我们使用$1和$2分别表示第1个参数和第2个参数,并将计算结果赋值给变量c,并在最后输出变量c的值。
在这里请思考一下:为什么我们的程序使用echo语句输出返回值,而不是使用return语句返回结果?
答案
因为两个数字相加的结果可能超过255。函数调用
在定义函数的基础上,调用函数就可以将函数看作是一个新的命令使用了。例如,对于我们定义的my_echo函数,在程序内就可以直接使用my_echo命令调用这个函数,从而输出“Hello”。
对于下面的add_function函数,类似于前面在介绍命令行传递参数一样,我们也可以使用类似的方式调用这个函数。下面的代码则完整展示了函数定义与调用的全过程:
#!/bin/bash
# 两个整数相加
function add_function() {
c=$(( $1 + $2 ))
echo $c
}
result=$(add_function 200 300)
echo ${result}
我们在第7行使用了一个赋值语句特别说明了如何将函数echo的返回值作为一般的返回值处理,也可以看到,对于这个例子,当计算200+300时,程序可以给出正确的结果(500)。
在一般使用时,我们也可以直接省略掉后面两行,而直接使用add_function 200 300也能输出类似的结果,当然,本例所给的方式更具有可扩展性。例如,你可以对这个结果进行进一步的计算,例如判断它是否大于255.(请试着完成这段代码)
最后,让我们再稍微扩展一下,如果用户在最开始给定一个数字个数,使用上面的函数,实现多个整数相加的结果。例如,用户一开始输入5表示有5个整数进行相加,然后会依次输入5个整数,程序输出5个数字相加的结果。我们在这里给出最终答案,请试着理解这段代码,并在理解后尝试自己写出来实现相同的效果:
#!/bin/bash
# 多个整数相加
function add_function() {
c=$(( $1 + $2 ))
echo $c
}
read -p "Please input a number" count
index=1
a=0
while [ $index -le $count ]
do
read b
result=$(add_function $a $b)
a=$result
((index++))
done
echo $result
在分析这段代码时,请务必考虑的内容是:while内部的循环条件为什么是这样(如果写成-lt会发生什么);为什么第15行要有一句a=$result,它的作用是什么?在整个程序中,index变量的作用是什么,为什么它的初始值设置为1;同时,为什么在开始时a有一个初始为0的值?
当你想明白这些答案时,相信这段代码就没有难度了。当然,我们这里是逐一计算的,那有没有办法在存下多个数据后一次性计算呢?这里的难点在于如何存储多个数据,这就需要下一节数组相关的内容了。
*数组
作者: Jiaqi Z.
知识点
- 如何初始化定义数组
- 如何调用数组的元素
- 如何定义“关联数组”
在上一节的最后,我们提到:需要有一种手段保存所有的元素。这在当时是一种可选的手段,除此之外,还有一个更常见的例子:假设我们现在需要计算一个班级所有同学考试的平均分,并在最后输出高于平均分的分数。此时,寻找一个方法用来存放所有数据就是必要的了。而与其他编程语言类似,在bash脚本中,也有类似于“数组”这样的数据结构。
在本节,我们将介绍如何在程序中显式定义1一个数组,以及如何调用数组的元素;在最后,我们再简单讨论一下关联数组的内容,这是一个类似于Python中“字典”的哈希表(Hash Map)结构。
定义数组
定义数组的方法并不困难,其基本格式为<变量名>=(value1 value2 value3 ...),其中数组变量元素整体用小括号括起来,且各个元素之间用空格间隔。例如,下面的程序我们定义了一个数组:
#!/bin/bash
# 定义数组
array1=(1 2 3 4 5)
array2=("Hello" "World")
array3=("Hello" 3 true)
在这段代码中,我们定义了三个数组,第一个数组array1和第二个数组array2分别是由数字和字符串组成的数组。在bash脚本中,数组不仅仅可以是数字,也可以是字符串或者其他数据类型。与C语言固定数组类型不同,在bash脚本中,一个数组内可以有多个数据类型,正如array3数组所演示的那样,其中可以包括字符串、数字、甚至逻辑值,都是可以放在一个数组变量下。
在定义数组时,与C语言不同,bash脚本不需要提供数组长度。换句话说,bash脚本的数组是可变长度的数组。
而且,与其他编程语言不同,bash脚本仅支持一维数组。
数组调用
与C语言类似的是,数组调用也是采用<数组名>[下标]的格式,其中下标是使用中括号括起来。一般数组的调用分为“读取”和“写入”两种情况,我们将依次讨论这两种情况的区别。
一个很关键的事情是:数组下标始终是从0开始计数的,即array1[0]表示数组array1的第一个元素。这件事情几乎是当今所有编程语言的基础2。
读取调用
下面的代码演示了如何读取数组的元素:
#!/bin/bash
# 定义与调用数组
array1=(1 2 3 4 5)
array2=("Hello" "World")
array3=("Hello" 3 true)
# 调用数组
result=$(( ${array1[0]}+${array1[1]} ))
echo $result
echo ${array2[0]}
if [ ${array3[2]} ]; then
echo ${array3[0]}
fi
上面代码的第7、9、10行分别演示了三种常见的调用方式,分别是在表达式中调用;在语句中调用;在逻辑表达式中调用。可以发现,无论哪一种调用方式,其格式基本是一样的,因此,读者完全不必将其分类到如此精确的程度,只需要记住一个原则:在读取时需要加$符号和大括号即可。
写入调用
在必要的时候,我们也可以对已有的数组进行修改。例如,下面的代码是对上面代码的进一步补充,并在其中演示了如何修改数组的元素值:
#!/bin/bash
# 定义与调用数组
array1=(1 2 3 4 5)
array2=("Hello" "World")
array3=("Hello" 3 true)
# 调用数组
array1[0]=5
result=$(( ${array1[0]}+${array1[1]} ))
array1[5]=$result
result[1]=${array2[0]}
if [ ${array3[2]} ]; then
array3[2]=false
fi
result[2]=${array3[2]}
for i in {0..2}
do
echo ${result[$i]}
done
在程序的第8行,我们将数组元素当作一般的变量,并对其进行赋值。但稍有难度的是第9行和第10行,其中第9行明明数组的最大下标为4(想想为什么5个元素的最大下标为4),但我们却可以对下标为5的元素赋值。在bash脚本中,这可以视作添加元素。与Python等语言可能还需要类似于append()函数不同,bash脚本只需要如同正常的数组进行操作即可,程序会自动追加新的元素在对应的位置。
更奇怪的是第10行代码:为什么result明明是一个普通变量,却可以带有下标追加新的元素?事实上,一个普通的变量也可以看作是一个长度为1的数组。正因如此,我们可以对普通变量如同数组般进行操作(追加新的元素),甚至对于普通的变量,例如定义了变量a=5,我们也可以使用a[0]来代表这个变量。
我们可以将整个数组看作一个一维的表格,其编号从0开始,每创建一个元素,就在对应位置加上内容。因此,你可以将下标设置成不连续的(例如,array1[10]是允许的,此时的数组如图所示)
正如图中所示的那样,数组前面也可以有元素(负下标),但这些除非特殊情况,否则不建议使用。同样,也正如你所见,对于没有的元素,其变量值为“空”。
除此之外,还有一些特别的方法对数组进行调用。例如,借助于*符号,我们可以获取数组内所有元素的值(其方法为<变量名>[*];使用#符号可以获取数组的长度。例如,对于数组array1,可以通过${#array1[*]}的方式获取其数组长度。
关于获取数组长度的方法,实际上近似等价于在介绍参数时(输入-参数输入)所提到的判断参数个数的方法。也如同当时所介绍的方法一样,这里的*也可以换成@符号。
*关联数组
在创建数组时,默认都是以数字作为下标。类似于Python中的“字典”结构,在bash脚本中我们也可以创建带有“键值对”的哈希表结构,称为关联数组。在定义关联数组前,需要使用declare -A的方式声明这个数组是关联数组。之后,就可以在下标中使用其他类型的数据(如字符串)对数组内的元素进行赋值。例如,下面的代码演示了如何定义与调用关联数组:
#!/bin/bash
# 定义与调用关联数组
declare -A data=(["name"]="Jiaqi Z.")
data["band"]="Roselia"
# 调用关联数组
echo "My name is ${data["name"]}, and I love ${data["band"]}."
在第3行,我们使用declare -A定义了一个“关联数组”,并在其中初始化了一个下标3为“name”的元素,其值为“Jiaqi Z.”。
在第4行,我们又如同调用一般的数组一样,对其进行赋值(追加了一个新的键)。之后在第6行调用了这个数组,并如同一般调用下标那样调用这个数组的“键”从而获得对应的“值”。
需要注意的是:在初始化定义时,需要特别指明元素的键(其基本格式如上面代码第3行那样),而在后续的使用中,则完全可将其视为特殊的数组使用(调用)
与前面所介绍的获取数组所有元素类似,对于“关联数组”而言,我们也可以使用<变量名>[*]的方式获得其所有元素的值。只不过在这里仅输出所有“值”(不包括“键”)。如果希望输出所有“键”的元素,可以在前面加感叹号(如!<变量名>[*])。例如,对于上面的代码,可以使用echo ${data[*]}的方式输出所有值,使用echo ${!data[*]}的方式输出所有“键”。
为什么要进行结构优化
作者: Jiaqi Z.
知识点
- 为什么要进行结构优化
- 结构优化的原理
在计算科学领域,一个广为流传的话是“Garbage In, Garbage Out!”,即错误的输入会得到错误的结果。因此,对材料计算而言,在进行任何材料计算之前,都需要保证输入的正确性,包括参数设置的正确以及结构的正确。其中,参数设置的正确性将取决于研究问题和研究经验,结构的正确则首先取决于结构优化。本章我们将介绍关于结构优化的一些设置方法与技巧。
在任何时候,开始一个新的体系进行计算,都需要进行本章所介绍的结构优化,哪怕这个材料是实验测得的或者数据库所给的。
为什么要进行结构优化
结构优化是指对整个输入体系的坐标进行调整,得到一个相对稳定的基态结构。例如,在计算材料的吸附性质时,我们需要通过结构优化得到一个“稳定”的吸附结构,从而测得吸附距离和其他稳定时的性质。如果需要确认材料的稳定性(例如计算声子谱),则显然需要首先进行结构优化以确保结构的“稳定”(甚至需要更高的精度)。
也许你会有一个疑问:如果结构已经实验测得,还需要结构优化吗?答案是需要,这是因为计算软件本身是考虑了许多近似情况,有时实验测得的结构和计算所使用的稳定结构有“细微”的区别。例如,对于氧气分子而言,使用数据库(CCCBDB)内的数据,其键长为1.2075 Å. 当我们使用不同的近似(考虑不同类型的赝势)进行结构优化1,得到的键长是不同的。使用O和O_s的赝势,在设置截断能为600 eV的情况下,计算得到的键长分别为1.23828 Å和1.29688 Å.
上面的键长变化可以极好说明对于不同的参数设置以及近似条件,所得到的结构可能是不同的。因此,哪怕是实验测得的或者数据库所给的,在开始计算时也需要进行结构优化。
结构优化原理
一个完整的结构优化计算,可以分为电子弛豫和离子弛豫两部分。首先,程序会计算许多步电子弛豫,以确定当前结构下稳定的波函数。基于密度泛函理论的基本原理,利用波函数可以得到体系的能量,判断能量是否达到极值点(大多数情况是判断原子平均受力);如果原子平均受力小于某一个设定的值,则认为结构已经“稳定”,否则会按照一定的算法对原子坐标进行移动,得到一个新的结构,再重复上述步骤,直到寻找到“稳定”结构。
上面我们所说的“稳定”,指的是能量达到一个“极值点”。而利用基本的数学与物理相关知识可以知道,真正的稳定结构(基态)应当对应结构能量的“最小值”,而寻找到的“极值点”不一定是最小值。
上述情况则会导致在有些情况下结构优化会得到一个“非最小值的极值点”,因此在实际计算时,可能还需要使用不同的初始结构进行结构优化,并通过能量比较确定最终的结构。一个典型的例子是计算吸附时需要考虑多个吸附位点,优化得到不同的结构,并通过能量比较确定最终的稳定吸附位点。
对坐标进行优化ISIF=2
作者: Jiaqi Z.
知识点
- 如何构建分子结构
- 如何对原子坐标进行结构优化
本节,我们将实现为什么要进行结构优化-为什么要进行结构优化中所介绍的氧气分子结构优化。首先,我们需要构建分子结构,并利用VASP进行结构优化,同时,我们将介绍如何查看关于结构优化的输出文件。需要特别注意的是,这一节的例子非常简单,但所介绍的内容(尤其是关于输出文件的理解)将有可能贯穿本章。
构建氧气分子结构
在VASP中,构建的所有结构都是需要基于晶胞进行构建,即所有结构默认都是周期性结构。有时,我们希望限制材料维数(例如二维材料、一维材料或分子、团簇),则需要在其他方向设置所谓的“真空层”以避免由于周期性所导致的材料之间的相互作用。
对于本节我们所考虑的氧气分子,由于是分子,因此在空间中可以是“孤立”存在的。在构建晶胞时在三个方向均设置较大的值以避免分子与分子之间的相互作用。在本例中,我们设置晶格常数为5 Å.
VASP在POSCAR中没有晶系的概念,构建的晶胞参数是基于“绝对空间坐标系”设置的。对于分子而言,晶系的设置不影响计算结果,我们可以设置为如三方晶系或更普通的三斜晶系等。但考虑到后续原子坐标设置方便,通常我们会将其设置为立方晶系。
但如果需要考虑其他体系,例如材料吸附气体等情况,为后续能量具有可比较性,晶胞的设置需要参考其他材料(例如,根据衬底材料的晶胞设置气体分子所使用的晶胞)
我们已经知道数据库内O2分子的键长为1.2075 Å,因此,设置的POSCAR文件如下所示:
O2
1.0
5.0 0.0 0.0
0.0 5.0 0.0
0.0 0.0 5.0
O
2
Cartesian
0 0 0
0 0 1.2075
这里为了设置方便,使用笛卡尔坐标设置原子坐标。在实际应用时,有时可能会借助其他软件如Materials Studio或者VESTA生成POSCAR文件,此时使用分数坐标(Direct)也是可以的。
如果你将上面的POSCAR文件放到VESTA文件进行预览的话,可能会发现有8个氧气分子(如图所示)。这并不是因为输入文件设置错了,而是因为VESTA在显示时考虑了周期性,8个氧气分子实际上是等价的。
INCAR设置
下面是一个简单的INCAR文件
ENCUT = 600
LWAVE = .FALSE.
LCHARG = .FALSE.
PREC = Accurate
NSW = 300
ISMEAR = 0
SIGMA = 0.05
IBRION = 2
ISIF = 2
EDIFFG = -0.01
-
ENCUT:截断能(单位:eV),根据所使用的POTCAR文件所决定,需要大于所使用POTCAR当中所有元素ENMAX的最大值,且通常至少为1.3倍的ENMAX。在本例中我们设置为600 eV; -
LWAVE和LCHARG:是否输出WAVECAR和CHGCAR文件(分别为波函数和电荷密度)。由于结构优化时通常不关心这些文件,因此设置为.FALSE.节省硬盘空间; PREC:计算精度,在进行结构优化时,为确保结构合理,通常设置为AccurateNSW:离子弛豫的最大步数。如为什么要进行结构优化-结构优化原理中所介绍的那样,结构优化需要进行多步离子弛豫直到收敛。若离子弛豫步数达到NSW则直接停止(哪怕没有收敛);-
ISMEAR:决定在布里渊区积分时,如何计算分布函数。当设置为0时表示使用Gaussian展宽,其展宽宽度由SIGMA参数决定(单位:eV); -
ISIF:设置为2表示仅优化原子坐标,不优化晶格; -
EDIFFG:当设置为正值时表示能量收敛标准,当设置为负值时表示原子之间的作用力收敛标准。
在本例中,我们设置ISIF=2,这是由于我们所优化的结构为分子体系,并不希望优化外面的晶格参数。除此之外,ISIF还有其他参数(常见的可能设置为3,在下一节介绍)。同时,通过设置EDIFFG决定收敛精度,通常设置为-0.01就已经达到了一般研究所需要的精度,但对于更高精度需求(例如计算声子谱),则可能需要到-1E-3的精度。
在实际使用时,可以考虑使用VASPKIT,使用vaspkit-101-LR或者vaspkit-101-SR,其中前者默认设置ISIF=3,而后者设置ISIF=2
其他输入文件
由于计算的是分子体系,不需要考虑周期性,因此在计算时KPOINTS的设置仅使用Gamma点即可。在生成时可以使用vaspkit-102-2-0生成Gamma点的KPOINTS。调用这个命令的同时也会生成默认的POTCAR文件。
计算结果分析
对于结构优化,我们重点关注OSZICAR和CONTCAR文件。执行上面的任务,所得到的OSZICAR文件如下所示(仅供参考):
(为排版方便,对小数点进行了截断处理)
N E dE d eps ncg rms rms(c)
DAV: 1 0.281908272337E+02 0.28191E+02 -0.56622E+03 192 0.105E+02
DAV: 2 -0.903395442264E+01 -0.37225E+02 -0.37218E+02 288 0.201E+01
DAV: 3 -0.907739062911E+01 -0.43436E-01 -0.43400E-01 192 0.111E+00
DAV: 4 -0.907742563069E+01 -0.35002E-04 -0.35001E-04 384 0.308E-02
DAV: 5 -0.907742563010E+01 0.58537E-09 -0.20560E-10 192 0.244E-05 0.457E+00
DAV: 6 -0.882350546712E+01 0.25392E+00 -0.36319E-01 288 0.584E-01 0.232E+00
DAV: 7 -0.876665612077E+01 0.56849E-01 -0.21667E-01 288 0.455E-01 0.528E-01
DAV: 8 -0.876722043380E+01 -0.56431E-03 -0.29377E-03 192 0.633E-02 0.946E-02
DAV: 9 -0.876743337124E+01 -0.21294E-03 -0.36429E-04 192 0.156E-02 0.840E-02
DAV: 10 -0.876745195297E+01 -0.18582E-04 -0.10996E-04 384 0.396E-03
1 F= -.87674520E+01 E0= -.87392430E+01 d E =-.876745E+01
N E dE d eps ncg rms rms(c)
DAV: 1 -0.808025287647E+01 0.68718E+00 -0.16093E+02 192 0.127E+01 0.305E+00
DAV: 2 -0.795453762419E+01 0.12572E+00 -0.39880E-01 192 0.592E-01 0.127E+00
DAV: 3 -0.794549043084E+01 0.90472E-02 -0.60348E-02 192 0.231E-01 0.485E-01
DAV: 4 -0.794766566379E+01 -0.21752E-02 -0.75618E-03 288 0.399E-02 0.116E+00
DAV: 5 -0.794386208834E+01 0.38036E-02 -0.20840E-03 192 0.313E-02 0.976E-02
DAV: 6 -0.794680317652E+01 -0.29411E-02 -0.26287E-04 192 0.224E-02 0.617E-02
DAV: 7 -0.794688859816E+01 -0.85422E-04 -0.60875E-05 384 0.439E-03
2 F= -.79468886E+01 E0= -.79186800E+01 d E =0.820563E+00
N E dE d eps ncg rms rms(c)
DAV: 1 -0.889539988611E+01 -0.94860E+00 -0.11596E+02 192 0.109E+01 0.256E+00
DAV: 2 -0.881026749441E+01 0.85132E-01 -0.25112E-01 192 0.539E-01 0.109E+00
DAV: 3 -0.880256066279E+01 0.77068E-02 -0.51306E-02 288 0.214E-01 0.822E-01
DAV: 4 -0.880096355131E+01 0.15971E-02 -0.13725E-02 192 0.253E-02 0.593E-01
DAV: 5 -0.880239330538E+01 -0.14298E-02 -0.25530E-03 192 0.526E-02 0.508E-02
DAV: 6 -0.880262470351E+01 -0.23140E-03 -0.19288E-04 192 0.153E-02 0.654E-02
DAV: 7 -0.880264094151E+01 -0.16238E-04 -0.68975E-05 192 0.261E-03
3 F= -.88026409E+01 E0= -.87744321E+01 d E =-.351890E-01
N E dE d eps ncg rms rms(c)
DAV: 1 -0.880299916057E+01 -0.37446E-03 -0.21780E-02 192 0.152E-01 0.391E-02
DAV: 2 -0.880298590664E+01 0.13254E-04 -0.11371E-04 288 0.121E-02
4 F= -.88029859E+01 E0= -.87747765E+01 d E =-.355340E-01
N E dE d eps ncg rms rms(c)
DAV: 1 -0.880299994411E+01 -0.78354E-06 -0.94840E-04 192 0.314E-02 0.592E-02
DAV: 2 -0.880305353569E+01 -0.53592E-04 -0.50512E-04 192 0.455E-03
5 F= -.88030535E+01 E0= -.87748689E+01 d E =-.356016E-01
其中每一个DAV开头的行表示电子步,当电子步达到收敛条件时则会计算离子步。在本例中,程序一共计算了5个离子步而达到收敛条件,从而结束计算。
在本例中,我们没有提供电子步的收敛条件。在VASP中,电子步的收敛是由EDIFF参数决定,默认为1E-4,单位为eV。
由于NSW参数,对于一些复杂的或者初始结构不合理的结构,有可能计算离子步达到NSW所设置的最大值仍未收敛。因此,可以通过查看OUTCAR文件中是否输出“reached required accuracy - stopping structural energy minimisation”从而确定结构优化是否收敛。
可以使用grep "reached required" OUTCAR命令查看。
结构优化的结果在CONTCAR文件中,你可以将其复制为POSCAR进行后续计算,也可以将其导出至如VESTA软件进行可视化分析。本例所计算得到的CONTCAR如下所示(仅供参考):
O2
1.000000000000000
5.0000000000000000 0.0000000000000000 0.0000000000000000
0.0000000000000000 5.0000000000000000 0.0000000000000000
0.0000000000000000 0.0000000000000000 5.0000000000000000
O
2
Direct
-0.0000000005038475 0.0000000006063874 -0.0030779335361196
0.0000000005038475 -0.0000000006063874 0.2445779335361217
0.00000000E+00 0.00000000E+00 0.00000000E+00
0.00000000E+00 0.00000000E+00 0.00000000E+00
相较于POSCAR,CONTCAR多输出了一部分(如上述文件中的最后两行)。它表示每个原子的初始速度,用于计算分子动力学(AIMD)。通常情况下,全部设置为0表示静力学计算。
对晶格常数进行优化ISIF=3
作者: Jiaqi Z.
知识点
- 如何对晶格常数进行优化?
- 如何固定晶格常数坐标?
在本节,我们将进一步讨论结构优化,考虑非分子、团簇情况,即对晶体结构的结构优化。与分子的情况不同,晶体结构需要考虑晶格常数的大小。在VASP当中,我们使用ISIF=3表示对晶格常数的优化。
首先,我们会展示一个简单的例子——对晶体硅进行结构优化,接着,我们将以二维材料为例,讨论如何对低维材料(如二维材料、一维材料)进行结构优化。其中,后者由于真空层的设置,在优化时可能需要一些其他设置。
三维材料结构优化
首先,我们需要构建Si的晶体结构。借助于Materials Project网站,可以下载到对应晶体的cif文件,并使用如VESTA等软件将其导出至POSCAR文件。作为练习,你可以参考下面的文件创建你的POSCAR文件:
Si2
1.0
3.8669745922 0.0000000000 0.0000000000
1.9334872961 3.3488982326 0.0000000000
1.9334872961 1.1162994109 3.1573715331
Si
2
Direct
0.750000000 0.750000000 0.750000000
0.500000000 0.500000000 0.500000000
可以发现,晶体Si为三方晶系(满足)。与优化分子不同,晶体需要同时进行原子坐标优化和晶格常数优化。与优化原子坐标类似,如果需要优化晶格常数,需要设置ISIF=3(其他参数可以参考对坐标进行优化ISIF=2一节中的INCAR设置。下面给了一个可以直接使用的INCAR文件:
ENCUT = 600
LWAVE = .FALSE.
LCHARG = .FALSE.
PREC = Accurate
NSW = 300
ISMEAR = 0
SIGMA = 0.05
IBRION = 2
ISIF = 3
EDIFFG = -0.01
可以直接使用vaspkit-101-LR生成。
也可以使用vaspkit-101-SR生成INCAR文件,但需要将ISIF设置为3(vaspkit在这一选项下默认设置为2)
与分子不同,对于晶格我们需要设置更多的k点(体现在KPOINTS文件中),通常在一个方向上的k点个数与晶格常数近似为即可。而在实际使用时,我们完全可以借助于vaspkit脚本,使用vaspkit-102-2生成以Gamma为中心的K点,输入需要使用的K点密度即可生成对应的KPOINTS文件(同时使用默认配置生成POTCAR)。我们使用0.06生成的KPOINTS如下:
K-Spacing Value to Generate K-Mesh: 0.060
0
Gamma
5 5 5
0.0 0.0 0.0
提交上述任务,完成后输出的CONTCAR文件为:
Si2
1.00000000000000
3.8715704308906274 -0.0000000000000000 0.0000000000000000
1.9357852154453137 3.3528783456576567 0.0000000000000420
1.9357852154453137 1.1176261152526314 3.1611240196775290
Si
2
Direct
0.7500000000000000 0.7500000000000000 0.7500000000000000
0.5000000000000000 0.5000000000000000 0.5000000000000000
0.00000000E+00 0.00000000E+00 0.00000000E+00
0.00000000E+00 0.00000000E+00 0.00000000E+00
可以发现,晶格常数相较于初始POSCAR发生了变化。同时,Si-Si键长从2.368 Å变为2.371 Å.
从原子坐标上看,似乎原子位置没有优化,但由于我们使用的是分数坐标,对于同样的原子坐标,不同晶格常数对应不同的键长与原子间相对位置。
*关于vaspkit的k点设置
无论你是计算新手还是有一定经验的“老手”,在使用vaspkit时可能产生过疑问:设置k点时输入的密度(例如0.06)到底是什么?上面的示例中为什么生成的k点个数就是?这一部分我们试图回答这一问题。
首先,k点所针对的是倒空间,而我们所使用的POSCAR都是针对于实空间的。通过实空间的晶格基矢,我们可以求得倒空间的基矢。例如,倒空间基矢就可以用下面的方式计算:
因此,我们可以通过实空间的晶格基矢长度,计算得到倒空间的基矢长度。例如,在本例中,基矢长度就是1.99.
而我们输入的密度,则可以定义为,其中为倒空间基矢的长度。例如,在本例中,倒空间基矢长度为1.99,则可以带入得到当时,可得.
或者,可以将密度解释为在中平均撒入个点,相邻两点的距离。
固定某一晶格常数的优化
对于低维材料(本节后续均以二维材料举例),为了避免层与层之间的相互作用,在构建结构时需要在垂直于平面方向的晶格常数设置较大的值(真空层)。以二维TiS2为例,在方向设置长度为15 Å的真空层,构建得到的POSCAR如下所示:
"Ti1 S2"
1.0
3.4143800735 0.0000000000 0.0000000000
-1.7071904305 2.9569396545 0.0000000000
0.0000000000 0.0000000000 15.000000000
Ti S
1 2
Direct
0.000000000 0.000000000 0.500000000
0.666670024 0.333330005 0.579720020
0.333330005 0.666670024 0.420280010
如果不加以限制,参考前面关于三维材料的结构优化所使用的设置,可以很容易想到(事实也会如此):真空层会发生变化。这在物理上没有实际意义,因此需要想办法对真空层(轴)进行固定。
使用OPTCELL文件进行固定
使用OPTCELL之前需要对VASP进行再编译,特别是需要重写文件constr_cell_relax.F。具体的编译原理请参考刘锦程博士的博客1,在此不再赘述。
如果无法配置,请联系你所在课题组的服务器运维人员。
在使用OPTCELL进行固定时,需要创建一个名为OPTCELL的文件,内部为的矩阵,例如,在本例中我们希望对真空层进行固定,则所创建的文件如下所示:
100
110
000
其中,1表示对某个坐标分量进行优化,而0表示固定(不优化)。
在OPTCELL当中,所有数字之间没有空格,这与下面要介绍的IOPTCELL不同。
使用IOPTCELL进行固定
肖承诚博士在github上提供了一个补丁2,可以通过在INCAR中设置IOPTCELL参数实现对晶格的固定。其基本原理是对通过构建力矩阵实现固定,假设原始的晶格常数构成一个的矩阵,IOPTCELL的作用就是设置一个的力矩阵,使得优化后得到的新晶格常数在需要固定的方向上元素值为0.
还是以上面的TiS2为例,当设置力矩阵为 时,可以实现新的晶格常数矩阵为 从而实现对真空层的固定。
在设置时,在INCAR里面提供参数IOPTCELL,按照列顺序书写(先写第一列,再写第二列,最后写第三列)。一共9个数字写在同一行且中间用空格分隔。例如,本例则可以设置为IOPTCELL=1 1 0 0 1 0 0 0 0
固定某些原子的优化
作者: Jiaqi Z.
知识点
- 如何在优化过程中固定某些原子
在对某些结构进行优化时,我们可能希望仅优化个别原子以加速优化过程。例如,对于气体吸附的过程,在没有确定最终吸附位置时,我们可能会希望先只优化气体分子的位置而将下方的衬底作为“背景”固定,从而找到一个近似合理的位置。在本节,我们将讨论这一类问题的实现方法。
如何固定原子坐标
无论是ISIF=2或者ISIF=3,优化过程都包括对原子坐标的优化。如果希望固定某个原子的坐标,则需要按照如下步骤操作:
- 在
POSCAR的原子个数下面一行添加Selective dynamics(只要保证首字母为S或s即可); - 在下方每个原子坐标后面使用三个逻辑值(
T或F)表示是否对这一坐标分量优化(或固定)(中间使用空格分隔)
还是以前面对坐标进行优化ISIF=2一节中关于O2分子的优化例子,如果我们希望固定某一个氧原子,而让另一个氧原子只在方向优化,则可以将POSCAR写成下面的样子:
O2
1.0
5.0 0.0 0.0
0.0 5.0 0.0
0.0 0.0 5.0
O
2
Selective dynamics
Cartesian
0 0 0 F F F
0 0 1.2075 F F T
其中,第10行使用三个F表示三个坐标分量均不进行优化,第111行使用F和T表示和坐标分量均不进行优化,而仅优化坐标分量优化。
使用的INCAR和KPOINTS与对坐标进行优化ISIF=2相同,这里仅列举如下而不做解释(方便读者直接阅读本节):
ENCUT = 600
LWAVE = .FALSE.
LCHARG = .FALSE.
PREC = Accurate
NSW = 300
ISMEAR = 0
SIGMA = 0.05
IBRION = 2
ISIF = 2
EDIFFG = -0.01
K-Spacing Value to Generate K-Mesh: 0.000
0
Gamma
1 1 1
0.0 0.0 0.0
优化得到的CONTCAR如下:
O2
1.00000000000000
5.0000000000000000 0.0000000000000000 0.0000000000000000
0.0000000000000000 5.0000000000000000 0.0000000000000000
0.0000000000000000 0.0000000000000000 5.0000000000000000
O
2
Selective dynamics
Direct
0.0000000000000000 0.0000000000000000 0.0000000000000000 F F F
0.0000000000000000 0.0000000000000000 0.2476911285012822 F F T
0.00000000E+00 0.00000000E+00 0.00000000E+00
0.00000000E+00 0.00000000E+00 0.00000000E+00
其中,氧原子的键长变为1.2385 Å,与之前所优化得到的键长(1.23828 Å)接近。同时需要特别注意的是:优化后第一个原子仍然在原点位置,而第二个原子仅坐标发生变化,从而实现了固定某些原子坐标的目的。
如何使用vaspkit快速固定特定原子的特定坐标
在vaspkit中,可以使用402-“Fix Selected Atoms”来固定特定的原子坐标。具体来说,在使用402后,选择1或2分别表示对POSCAR或CONTCAR进行操作(也可以使用3指定具体的文件,但这通常用不上。你总不能真有个文件叫YUKINACAR吧)
假设我们对POSCAR里面的特定原子进行固定,在选择文件后会让选择要怎样选择固定原子。通常来说使用1即可(即按照POSCAR里的原子编号固定)。例如,我们选择固定前12个原子,则在这里选择1-12。如果是固定第1个和第3个原子,则写作1 3,中间用空格分隔。
之后,会让选择固定坐标,其中1-3分别表示固定x,y,z坐标,可以多选(使用空格分隔)。特别地,如果你希望固定所有坐标,则直接输入all也行。完成后会生成一个以_FIX.vasp结尾的文件(如果是使用POSCAR生成的,则会生成POSCAR_FIX.vasp文件),将其复制为你要处理的文件即可(无论是改成POSCAR或者下载到本地使用VESTA打开都可以)
当固定坐标优化完成后,可能会需要释放约束让其进一步优化,则直接使用sed命令把F修改为T即可。关于sed命令如何使用,在Linux部分的“高级Linux命令-sed文本替换”里有详细介绍,这里就不说了。
一些结构优化的策略与加速方法
作者: Jiaqi Z.
知识点
- 为什么要进行分步优化
- 一些分步优化时需要注意的参数与方法
如果你所研究的材料是很简单的材料,甚至是数据库或实验已经测得的,当你用这一结构进行结构优化时,其速度往往是很快的(至少相较于后面所要讨论的那些而言)但如果这个结构是不确定的,例如,你需要研究一种经过某种方式调控的材料,或者是两种组分相互作用形成的体系(例如气体吸附),现成的数据往往不足以构建一个完全符合实际的结构。因此,你需要通过结构优化这一步寻找合理的体系结构并进行后续的计算。
但是,一个初始不合理的结构,其优化时长通常可能以小时或天计,而且其优化结果不一定合理,从而耽误后续计算。因此,在这一节,我们将介绍一种结构优化策略——分步优化。通过逐步提高精度,快速找到体系的合理结构。
使用Gamma点
在优化周期性结构时,我们通常会使用一定大小的k点来提高计算精度。但对于初始而言,这种密度往往会造成不必要的时长,而且在初始结构不合理的时候,使用一个较小的K点也足以帮助我们找到一个大致正确的结构。此时一个较合理的方法是使用Gamma点。
如果是使用vaspkit生成的KPOINTS,只需使用vaspkit-102-2-0即可生成仅有Gamma点的KPOINTS。可以比较发现,使用这一方法可以较大提高计算速度。
如果只使用Gamma点计算,在vasp计算版本中可以使用vasp_gam版本计算。修改方法通常在提交任务脚本中。例如,以我所在课题组为例,对于105、106和224节点,只需要在已有提交脚本中找到vasp_std并将其修改为vasp_gam即可。
固定相互作用较弱的原子
对于某些体系,例如气体吸附,气体分子与靠近气体分子的一层原子的相互作用应当明显大于远离气体分子的那一层原子。因此,在进行低精度结构优化时,可以优先将相互作用较弱的原子进行固定,而只优化相互作用较强的原子,从而使其快速找到合适位置。
以气体吸附为例,在初始结构不合理的时候,可以将吸附衬底固定而只优化气体分子所在位置,从而将其移动到大致正确的位置,再进行后续高精度优化。
使用低精度参数
如果你所需要的优化精度(如EDIFF,EDIFFG等)较高,可以优先使用低精度进行优化,再将其逐渐提升到高精度,从而使其快速收敛到合适位置。
在必要的时候,稍微调大POTIM参数从而增大迭代步长进行快速优化也是合理的,但其参数的调整需要人为“监控”以避免出现不合理的情况(例如,步长过大导致迭代不收敛)。
在调整EDIFF和EDIFFG时,如果EDIFF设置精度较低而EDIFFG设置精度较高,有可能会发生力难以收敛的情况。因此,在提高二者精度时,可以先提高EDIFF的精度,再提高EDIFFG的精度1。
此外,在进行结构优化参数设置时,一些与结构可能无关的参数初始也可以不设置(例如,对于没有范德华作用体系的结构,考虑范德华作用则是多余的)。但是,磁性考虑与否可能会影响结构,因此,在进行分步优化时,应当考虑磁性(ISPIN=2)以避免磁性对结构的影响。
什么是静态自洽
作者: Jiaqi Z.
知识点
- 什么是静态自洽
- 为什么要进行静态自洽
在本章,我们将开始讨论电子性质的计算。电子性质的计算范围非常大,小到体系的能量,大到计算体系的能带、态密度等都是对材料电子性质进行计算。一些复杂的计算如能带、态密度等我们放到后面的章节单独介绍,而一些简单的性质将在本章进行说明。
什么是静态自洽
在结构优化中介绍过,在进行任何材料的计算前,都需要进行结构优化。结构优化是VASP计算的第一步,旨在通过调整输入体系的坐标,得到一个相对稳定的基态结构。这个过程包括原子迟豫和电子迭代两个嵌套的过程。每次计算中都进行原子迟豫和电子迭代计算,直到达到自动中断或者最大原子迟豫步数。
相比之下,静态自洽计算(self-consistent field method, SCF)是在结构优化的基础上进行的。此时,原子位置保持不动,只对电子进行自洽计算,以达到体系的最低能量。静态自洽计算前需要使用结构优化输出的CONTCAR文件,并将其拷贝成新的POSCAR文件。
在VASP计算中(甚至包括其他大多数材料计算软件),自洽方法的基本思想都是先按照某种方法给出波函数的一个估计,然后利用这个估计来计算电子密度,再通过电子密度来得到哈密顿量中与粒子间相互作用有关的项,再进行薛定谔方程的求解得到一组改进的估计。
为什么要进行静态自洽计算
计算静态自洽的本质是为了得到体系的电子性质,在以下几种情况下,你可能会需要计算静态自洽:
- 计算能量、磁矩等性质:要得到体系的能量,首先需要得到能量最低时的电子密度(这是“密度泛函理论”的基本假设);虽然在计算结构优化时也可以得到一个能量,但有时结构优化为了提高计算效率,可能会忽略一些与结构影响无关的近似(如范德华校正等),但这些近似会影响计算的能量值。在实际计算时,我们可能会在自洽计算过程中考虑更多的近似;
- 计算态密度、能带等电子性质:其本质上也是为了计算得到电子结构性质;
- 计算电荷密度图等性质:这种直接计算电荷密度的性质,也必然要进行自洽计算。
在本章,我们主要讨论能量、磁矩、电荷密度(特别是常见的“差分电荷密度”)的计算方法。它们的计算大多只需要一些简单的物理知识即可说明清楚。一些更深入的电子性质(如bader电荷转移、电子局域函数ELF、晶体轨道布居COHP等)将在后面的章节进行讨论,它们有些需要更复杂的物理知识,甚至可能需要一些更复杂的计算(借助其他程序包)。
能量计算
作者: Jiaqi Z.
知识点
- 如何计算体系的能量
- K点与截断能测试
在本节,我们将讨论在计算中最重要的一个物理量——能量。如果你是要计算吸附或类似的(两个体系相互作用的能量),肯定需要计算两个体系的能量(甚至可能还需要计算更多)。此外,在实际计算的时候,为节省机时,选择合适的精度也很重要(尤其是对那些花钱买机时的课题组而言更是如此)。而考虑精度是否合适的一个标准,就是计算能量的精度。
自洽计算能量
让我们直接看一个例子——计算单晶Si的能量。首先,我们需要构建Si的结构,也就是POSCAR文件。在对晶格常数进行优化ISIF=3一节中我们已经构建了它的结构,这里直接写出其POSCAR文件:
Si2
1.0
3.8669745922 0.0000000000 0.0000000000
1.9334872961 3.3488982326 0.0000000000
1.9334872961 1.1162994109 3.1573715331
Si
2
Direct
0.750000000 0.750000000 0.750000000
0.500000000 0.500000000 0.500000000
首先需要进行结构优化,具体方法详见对晶格常数进行优化ISIF=3,这里不再赘述。假设你已经优化完成了,得到了CONTCAR文件,将其复制到一个新目录下1,将其命名为POSCAR。我们后续的大多数计算都是围绕这个结构来的。
在此基础上,自洽计算所使用的INCAR如下:
ISTART = 1
ISPIN = 1
LREAL = .FALSE.
ENCUT = 600
LWAVE = .FALSE.
LCHARG = .FALSE.
ADDGRID= .TRUE.
LASPH = .TRUE.
PREC = Accurate
ISMEAR = 0
SIGMA = 0.05
NELM = 60
EDIFF = 1E-5
其中,有一些参数需要解释一下:
ISPIN:表示自旋极化开关,当设置为1时表示不开启自旋极化,当设置为2时表示开启。这一选项是进行磁性材料计算的重要参数,我们将在磁矩计算一节详细介绍;NELM:表示最大自洽迭代次数,当达到最大次数时,vasp将停止计算;EDIFF:表示自洽迭代的精度,单位为eV,当两次自洽前后能量差小于其数值时,表示达到收敛精度,结束计算。默认值为1E-4
其他参数与结构优化保持一致,完成后查看OUTCAR文件中在靠近最后的位置有类似下面的输出内容:
FREE ENERGIE OF THE ION-ELECTRON SYSTEM (eV)
---------------------------------------------------
free energy TOTEN = -10.78671596 eV
energy without entropy= -10.78671596 energy(sigma->0) = -10.78671596
可以看到,这里面有三个能量。通常来说,由于我们的计算能量更多是讨论它们的相对值而不是绝对值,因此在实际计算时选择某一个特定的能量,并采用同一标准进行计算即可。通常来说,我们使用第三个能量energy(sigma->0)作为体系能量。
在这里你也许已经注意到了,从这一部分开始,我们可能不会在所有地方给出全部的输入文件了。例如,在这里我们并没有给出KPOINTS文件。这也是为了给读者更多的能动性(Your task your way,你的计算任务你做主)。
也正因如此,后面有些具体的数值可能与你计算结果不相同,但大体趋势应当是一致的。
另外,你也应当注意的是,在计算任务中使用的截断能(ENCUT)应当始终保持一致。我们的例子可能会给出具体的截断能数值,你完全可以按照你的参数选择你想要的数值。这无所谓,但是,在后面我们会提到一个截断能的最小值。无论是你的还是我的,设置的ENCUT都不应当小于这个最小值。
既然已经讨论到这里了,我们就简单介绍一下三个能量表示的含义。其中,free energy TOTEN表示自由能(吉布斯自由能),其表达式为,由于我们的计算不考虑温度(绝对零度),因此按理来说,无论熵怎么变化,对能量的影响都没有影响。而事实上,由于我们的计算采用Gaussian展宽(ISMEAR=0),在实际计算时会引入在费米能级附近变化的电子态,从而引入了误差(具体来说,是引入了“温度”)
energy without entropy表示不考虑熵时的自由能,energy(sigma->0)表示当展宽趋向于0时的能量。在本例中,这三个能量值相等,但这不总是绝对的。之所以如此,是因为我们计算的Si是半导体,且设置的展宽合理,从而导致电子占据与实际情况接近(在OUTCAR中,我们可以看到电子的占据情况(occupation)。如果展宽过大(例如在本例中,如果设置SIGMA=1,再次计算能量,则有可能有下面的情况:
FREE ENERGIE OF THE ION-ELECTRON SYSTEM (eV)
---------------------------------------------------
free energy TOTEN = -10.83981213 eV
energy without entropy= -10.66813608 energy(sigma->0) = -10.75397411
可以发现,三个能量是不相等的。但一般来说,第三个能量(展宽为0时的能量)总是等于前两个能量的平均值。
此外,当我们使用ISMEAR=-5(表示正四面体方法时),其计算严格按照费米能级定义,此时的三个能量应该相等。也正因如此,在计算半导体或绝缘体时,由于存在费米能级(电子填充的最高态),因此使用ISMEAR=-5会得到更准确的结果。但这是以计算效率为代价。也正因如此,在计算导体时,千万不要使用ISMEAR=-5计算!
在能量计算的时候,通常绝对值是没有意义的,因为这个数值涉及到零点的选择。类似于普通物理(电磁学)中对带电粒子能量的讨论,通常我们选择无穷远处为零势能面,其能量为0,从而得到带电粒子的能量。在这里情况是类似的——能量的零点是可以自由设置的,因此我们没有办法讨论具体的能量值。但能量的相对值是确定的。例如,我们永远无法说一个物体的势能是多少(这涉及到零势能面选取),但当讨论势能变化时,无论怎么选取零势能面,其结果都是确定的。
正因如此,在论文中,我们需要尽量避免出现绝对能量,而使用相对能量(如吸附能、结合能等都是通过体系能量差值定义的)
使用能量进行收敛性测试
在计算一个体系之前,首先是需要对体系进行收敛性测试,以选择合适的参数,从而兼顾效率和精度。通常涉及到的收敛性测试包括截断能和K点,越高的截断能,越精细的K点,计算得到的精度越高,但这会带来更多的计算机时成本。因此,在进行计算前应该想办法找到合适的精度,这一方法就是收敛性测试。
具体来说,所谓收敛性测试,就是通过改变参数做自洽计算,得到体系能量随参数的变化。通常来说,每原子能量变化在1 meV以下时,表示体系精度收敛,可以进行后续计算。
截断能测试
同样还是前面的Si单晶,在实际计算时,我们都是先进行收敛性测试。因此,我们使用最开始的POSCAR。创建若干个截断能测试目录,并将计算任务复制到里面,改变截断能参数(在这里,我们取200、250、300、350、400、450、500、550、600、650、700),分别计算这些任务,并考察能量变化。
在创建测试目录时,你当然可以直接创建,但更简单的方法是使用for循环。具体的方法在讲解Linux时的简单for循环-一些for循环使用例一节有详细介绍,这里不赘述。如果你看到这里再回头看那一部分就会发现,当时的例子就是为了解决这一问题。
计算完之后查看能量随截断能的变化,处理数据如图能量计算-截断能收敛性测试所示。可以发现,随着截断能的增大,体系能量逐渐减小(蓝线),但在400 eV之后能量减小得更慢,甚至已经达到了前面所说的收敛标准(每原子能量变化在1 meV以下,见红线),因此,在后续计算时,使用400 eV作为截断能就足够了。

在截断能的选择上,通常有一个理论最小值,也就是你所选择的赝势中ENMAX的最大值。设置的截断能必须比这个数值大才有可能保证准确性。例如,在本例中,如果查看我们使用的Si的赝势,里面有ENMAX = 245.345,表明我们计算时所使用的截断能必须比这个数值大。通常情况下,使用ENMAX的1.3倍到1.5倍是合适的。
虽然我们多次说明:在计算时应当指定截断能,但事实上ENCUT本身是有默认值的,这个默认值就是赝势文件中ENMAX的最大值。尽管如此,对于不同的体系可能会有不同的默认值,在计算时为了统一,还是应当设置ENCUT。
K点测试
关于K点的测试,方法与截断能完全类似,这里只给出最终结果如图所示。可以发现,当K点取时,体系能量收敛。

上述收敛性测试的例子仅是一个参考,实际情况还需要结合机时与计算时间综合考虑。此外,在这里我们所给出的结果是计算前用来做参数测试的步骤,在后续教程中,我们都不会进行这一步。其中有一些情况是结合经验选择的参数,有些是做过收敛性测试。在实际计算时,应结合实际情况选择参数。
磁矩计算
作者: Jiaqi Z.
知识点
- 如何计算体系磁矩
- 如何根据能量确定磁基态
- 如何查看磁矩分布
- 绘制自旋密度图
这一节,我们将介绍如何计算磁性材料,主要考察它们的磁性,以及磁矩分布等问题。结合前面的能量计算,我们还有可能接触到一点关于铁磁和反铁磁的性质讨论。
计算体系磁矩ISPIN=2
下面这个例子,计算了一个单原子Si的磁矩。之所以先计算单原子,是因为单原子的磁矩比较容易分析。首先,我们先构建只有一个Si原子的POSCAR
Si
1.0
5.0 0.0 0.0
0.0 5.0 0.0
0.0 0.0 5.0
Si
1
Direct
0.5 0.5 0.5
接下来构建INCAR文件
ISTART = 1
ISPIN = 2
LREAL = .FALSE.
ENCUT = 600
LWAVE = .FALSE.
LCHARG = .FALSE.
ADDGRID= .TRUE.
LASPH = .TRUE.
PREC = Accurate
ISMEAR = 0
SIGMA = 0.05
NELM = 60
EDIFF = 1E-5
这个参数与能量计算一节所使用的几乎完全相同,唯一有一个不同的地方是ISPIN设置为2,表示开启自旋极化。此外,由于我们是计算单原子(不考虑重复单元),与计算分子类似,使用的KPOINTS。
由于是计算单原子,因此也不存在结构优化这回事。毕竟一个原子无论从晶格还是坐标都没有可优化的地方(哪怕分数坐标从0.5变成0.6也没有任何意义)。
这件事与计算分子不同,分子需要进行坐标优化(涉及到键长),也就是对坐标进行优化ISIF=2一节所介绍的例子。
当计算完成后,我们考察OSZICAR文件,与ISPIN=1不同的地方在于,每一个离子步后面多了一个mag表示体系磁矩。关注最后一行的mag,其数值就表示体系的磁矩。在本例中,最后一行的OSZICAR如下所示:
1 F= -.44168179E+00 E0= -.42239900E+00 d E =-.385656E-01 mag= 2.0000
表示体系的磁矩为2.0,单位为玻尔磁子$\mu_\text{B}$,这一结论与Si原子的电子排布结论相同\footnote{正如原子物理或者高中化学所介绍的那样,Si有两个3p孤立电子,从而表现为磁矩为2.0 $\mu_\text{B}$}。但是,如果我们考察一下VASP计算得到的电子占据(无论从EIGENVAL文件读取还是从OUTCAR最后查看不同能量的电子排布),都会发现类似下面的情况(我们这里以OUTCAR为例):
spin component 1
k-point 1 : 0.0000 0.0000 0.0000
band No. band energies occupation
1 -9.4957 1.00000
2 -2.2461 0.66667
3 -2.2461 0.66667
4 -2.2461 0.66667
5 0.7529 0.00000
6 3.1135 0.00000
7 3.1135 0.00000
(略一部分)
spin component 2
k-point 1 : 0.0000 0.0000 0.0000
band No. band energies occupation
1 -7.7339 1.00000
2 -0.4696 0.00000
3 -0.4696 0.00000
4 -0.4696 0.00000
5 1.5279 0.00000
6 4.1230 0.00000
(下略)
可以看到,对于spin为1的状态,电子占据数出现了0.66667这样的小数,这显然是不合理的。之所以出现这个结果,是因为在计算时出现了“简并”,即出现了三个能量是-2.2461的轨道,且由这三个轨道均分两个电子,从而每个轨道分得0.66667(也就是三分之二)个电子。
在这里我们说spin为1的状态,并没有特指自旋向上或向下。事实上,自旋方向是人为定义的,你可以说spin为1是自旋向上,也可以说它是自旋向下。
在本教程中,若无特殊说明,我们默认spin为1表示自旋向上,磁矩为正表示自旋向上。
之所以产生这个问题,一个原因是我们所使用的晶格常数对称性太高了。如果我们想办法减小一点对称性,将POSCAR中的晶格常数改为5.0 5.5 5.9,再次进行计算,结果在保持磁矩为2.0不变的前提下,电子占据也会变得正常:
spin component 1
k-point 1 : 0.0000 0.0000 0.0000
band No. band energies occupation
1 -10.0597 1.00000
2 -3.3334 1.00000
3 -3.1172 1.00000
4 -2.6324 0.00000
5 -0.0094 0.00000
6 2.0529 0.00000
7 2.6188 0.00000
(略一部分)
spin component 2
k-point 1 : 0.0000 0.0000 0.0000
band No. band energies occupation
1 -8.5155 1.00000
2 -1.9085 0.00000
3 -1.3910 0.00000
4 -1.0711 0.00000
5 0.6883 0.00000
6 2.8908 0.00000
(下略)
此时自旋向上有3个电子,自旋向下有1个电子,与实际排布情况相同1。
使用MAGMOM设置初始磁矩
下面我们将进一步讨论多原子体系,讨论两个Cr原子组成的体系,其POSCAR如下所示2:
Cr2
1.0
2.9688993551160281 0.0000000000000000 0.0000000000000002
-0.0000000000000002 2.9688993551160281 0.0000000000000002
0.0000000000000000 0.0000000000000000 2.9688993551160281
Cr
2
direct
0.0000000000000000 0.0000000000000000 0.0000000000000000 Cr0+
0.5000000000000000 0.5000000000000000 0.5000000000000000 Cr0+
与单原子不同的地方在于,首先需要对体系进行结构优化(使用ISIF=3)。但与对晶格常数进行优化ISIF=3不同的地方在于,对磁性材料进行结构优化时也应当开启ISPIN=2。
自旋极化打开与否是会影响体系结构的,甚至不同的磁性都有可能产生不同的结构。
完成后进行静态自洽计算,与前面的讨论接近,使用如下的INCAR:
ISTART = 1
ISPIN = 2
LREAL = .FALSE.
ENCUT = 450
LWAVE = .FALSE.
LCHARG = .FALSE.
ADDGRID= .TRUE.
LASPH = .TRUE.
PREC = Accurate
ISMEAR = 0
SIGMA = 0.05
LORBIT = 11
NELM = 60
EDIFF = 1E-5
有一点不同的地方,在于设置了LORBIT参数。当LORBIT=10时表示将轨道投影到,而LORBIT=11则可以进一步将轨道投影至如等。在本例中,使用LORBIT=10或LORBIT=11均不影响结果。
计算完成后,查看OSZICAR,发现体系磁矩为0,表示体系没有磁性。当设置LORBIT之后,我们可以通过OUTCAR查看每个原子的磁矩。在接近最后的位置,可以有如下输出内容:
magnetization (x)
# of ion s p d tot
------------------------------------------
1 0.000 -0.000 -0.000 -0.000
2 0.000 -0.000 -0.000 -0.000
--------------------------------------------------
tot 0.000 -0.000 -0.000 -0.000
其中原子编号是按照POSCAR顺序,里面的tot一列表示原子的总磁矩(沿轴方向),可以发现,每个原子的磁矩都为0.
我们这里所说是沿着轴方向的磁矩,但实际计算时当然可以指定具体方向,具体来说,这个过程涉及到非共线计算(LNONCOLLINEAR设置为.TRUE.,同时设置LSORBIT为.TRUE.开启自旋轨道耦合(Spin-orbit coupling, SOC),并在SAXIS里设置量化轴方向。
此外,在计算SOC时,还应当使用非共线版本的vasp(目前默认使用的都是vasp_std),需要将“std”改为“ncl”。
但是,事实真的如此吗?如果是从Materials Project下载的数据,可以看一下上面对磁性的描述,是Antiferromagnetic,也就是反铁磁。所谓“反铁磁”,指的是“在没有外部磁场的情况下,材料内部相邻原子的磁矩相互抵消,形成反平行排列的状态。这种排列使得材料在宏观上不表现出磁性,即净磁矩为零”。但是,我们如何想办法得到这个反铁磁态呢?就需要在计算时设置MAGMOM参数给定初始磁矩。
在这里,我们假定每个原子的磁矩是6,这是我们已知的原子磁矩。在原先的INCAR中添加MAGMOM = 9 9表示设置第一个原子的磁矩为9,第二个原子的磁矩为9。
在设置MAGMOM时,你可以像这里这样直接给出每个原子的磁矩(按照POSCAR顺序),如果原子数较多,也可以使用*批量设置,其格式为[number]*[mag],其符号前后没有空格,但每一组之间用空格分隔。例如,MAGMOM=16*0 1*2表示前十六个原子磁矩为0,后一个原子磁矩为2.
在这里我们设置的磁矩是初始磁矩,VASP会有方法将其收敛到合适的值。通常来说,我们要给的初始值应当比真实值大,在这里我们设置为9,当然设置为其他数值也是可以的。但不同的初始值可能会计算到不同的磁矩。
此外,正如前面所说的那样,不同的磁矩会影响不同的结构,因此在设置MAGMOM时需要从结构优化开始。
无论你是怎样设置的磁矩,在计算后得到的磁矩与上面的OUTCAR接近。查看体系的能量,发现约为-19.03 eV。如果我们尝试设置为反铁磁态(即两个原子的磁矩相反),例如,设置MAGMOM=-9 9,重复上面的结构优化与自洽计算,会发现能量为-19.06 eV,比前面的能量更低。这一结论表明后面的状态为更稳定的基态(有时也管这种状态叫磁基态)。当我们进一步考察其OUTCAR时,可以发现结果为:
magnetization (x)
# of ion s p d tot
------------------------------------------
1 -0.014 -0.008 -1.078 -1.100
2 0.014 0.008 1.078 1.100
--------------------------------------------------
tot 0.000 0.000 0.000 0.000
其中第一个原子和第二个原子磁矩大小相同,方向相反,总磁矩表现为0(在OSZICAR中可以查看),这种状态就是反铁磁。
我们在这里只讨论MAGMOM=9 9和MAGMOM=-9 9的情况,对于另外两种情况(-9 -9和9 -9),其本质与前面两种相同。正如前面所说的,自旋方向是相对的,两个都自旋向上,与两个都自旋向下,结果是一样的。
我们在这里介绍了MAGMOM的两种设置方法,除此之外还有第三种,即设置原子沿每个轴的磁矩。这一设置需要使用前面所介绍的“非共线计算”(LNONCOLLINEAR=.TRUE.)。这里暂不介绍,如有需要,可查看VASP对MAGMOM的介绍3。
自旋密度图可视化
在前面的计算中,我们已经找到了Cr的磁矩分布,但在论文中,有时为了强调磁矩的分布情况(如具体是哪个原子提供磁矩,磁矩方向如何等),我们会考虑绘制自旋密度图。具体的计算方法与上面所讨论的类似,但唯一需要修改的一个参数是LCHARG=.TRUE.生成CHGCAR文件。具体来说,下面是一个完整的自洽计算的INCAR例子:
ISTART = 1
ISPIN = 2
MAGMOM = -9 9
LREAL = .FALSE.
ENCUT = 450
LWAVE = .FALSE.
LCHARG = .TRUE.
ADDGRID= .TRUE.
LASPH = .TRUE.
PREC = Accurate
ISMEAR = 0
SIGMA = 0.05
LORBIT = 11
NELM = 60
EDIFF = 1E-5
具体的绘制方法,使用vaspkit-312的“Spin Density”功能处理,之后生成SPIN.vasp文件,将其拖动到可视化软件VESTA当中,稍微调整一下等值面(在“Properties”-“Isosurfaces”当中),这里设置为0.01,如图所示:

可以发现,中间的原子与角上的原子自旋方向不同,与我们的结论一致。
电荷密度与差分电荷密度
作者: Jiaqi Z.
知识点
- 如何绘制电荷密度图
- 如何绘制差分电荷密度图
这一节的内容并不难,但却是很多文献里都会放的一部分。在本节,我们将介绍如何绘制差分电荷密度图,很多文献都会通过这张图判断两个原子之间的成键性质,以及电荷转移情况。
使用LCHARG绘制电荷密度
本节我们要讨论的例子是NaCl这一典型材料,正如你在中学或大学了解到的那样,NaCl是离子晶体,其成键性质表现为Na失电子而Cl得电子。首先,我们需要构建出它的结构1:
Na4 Cl4
1.0
5.5881264354399347 0.0000000000000000 0.0000000000000003
-0.0000000000000003 5.5881264354399347 0.0000000000000003
0.0000000000000000 0.0000000000000000 5.5881264354399347
Na Cl
4 4
direct
0.00 0.00 0.00 Na+
0.00 0.50 0.50 Na+
0.50 0.00 0.50 Na+
0.50 0.50 0.00 Na+
0.00 0.00 0.50 Cl-
0.00 0.50 0.00 Cl-
0.50 0.00 0.00 Cl-
0.50 0.50 0.50 Cl-
首先进行考虑晶格常数的优化。完成后进行自洽计算,使用的INCAR如下所示:
ISTART = 1
ISPIN = 1
LREAL = .FALSE.
ENCUT = 350
PREC = Accurate
LWAVE = .FALSE.
LCHARG = .TRUE.
ADDGRID= .TRUE.
ISMEAR = 0
SIGMA = 0.05
NELM = 60
EDIFF = 1E-5
与前面的自洽计算相比,要注意LCHARG参数需要设置为.TRUE.表示输出CHGCAR文件。计算完成后会得到CHGCAR文件。将其下载并在VESTA中打开,调整等值面大小(例如设置为0.05)并修改颜色,得到的电荷密度图如图所示。可以发现,对NaCl而言,电子主要集中在Cl原子附近,这与我们前面对NaCl的认识一致。

从数据的可视化角度出发,当然也可以使用二维数据,如图所示,其结论与上面一致。只是从可视化角度可能更直观一点。

绘制差分电荷密度图
下面我们要绘制差分电荷密度图,在绘制之前,我们首先需要明确;什么是差分电荷密度。如果一个体系由两部分A和B组成,其总电荷分布为,当仅存在A体系时的电荷分布为,类似地仅存在B体系时地电荷分布为。则差分电荷密度定义为
可以发现,当某个地方的电荷数增多时,差分电荷为正,反之,当电荷减少时,差分电荷为负。也可以发现,在计算差分电荷密度之前,我们首先需要有三个体系的电荷密度(AB体系、A体系、B体系)。每一个体系的差分电荷计算都如上面所介绍的方法一样。采用类似的方法,得到三个体系的电荷密度。
在计算不同体系的电荷密度时,不需要进行结构优化,而直接在AB体系中删去另一个体系的原子即可。
此外,在计算时应当保持参数一样,尤其是k点密度。
在本例中,A、B体系分别是Na原子和Cl原子组成的体系,计算得到电荷密度后可以直接使用vaspkit-314“Charge-Density Difference”功能,分别输入AB体系、A体系和B体系的CHGCAR文件(使用相对路径2),会得到CHGDIFF.vasp文件,将其用VESTA打开,调整可视化选项,即可得到差分电荷密度图如图所示。可以发现,在Cl原子附近电荷增多,表现为得电子。

与电荷密度类似,这里也可以绘制二维甚至一维差分电荷密度图(也可以叫平面平均差分电荷密度图)。
*如何绘制平面平均差分电荷密度图
平面平均差分电荷密度图,指的是对某一平面内的差分电荷密度做平均计算,并绘制沿另一个方向(通常是轴)的变化曲线。例如,在二维材料里(比如异质结),通过这种方法可以看出不同材料之间在界面处的电荷转移情况(如图所示3)。

一般来说,平面平均差分电荷密度图用于二维材料相互作用,且绘制方向通常沿着真空层方向。在本例中,我们尽管可以绘制某种平面平均差分电荷密度图,但没有什么明显结论,仅作为步骤演示,不展示结果。
在绘制的时候,首先需要在当前计算差分电荷密度的目录(即有CHGDIFF.vasp文件的目录),使用vaspkit-316“1D Planar-Average Charge Density”功能,选择3-Specified Charge Density File并输入CHGDIFF.vasp(差分电荷密度文件),完成后会生成PLANER_AVERAGE.dat文件,将其放入origin作图即可。